
[想定している読者像]
お客様より広告効果を問われている広告代理店のプランナーの方。
代理店レポートではなく自社で広告効果を検証したい、広告主のマーケテイングマネージャー、ブランドマネージャーの方。
lightweight MMMを実際に動かしてみたいデータアナリストの方。
[コンテンツ属性]
ビジネス:★★★☆☆
データアナリティクス:★★★★★
エンジニアリング:★☆☆☆☆
2023年7月更新内容
- ligthweightMMMの0.1.9が5月にリリースされたので、それにもとづいて内容を更新しました。
- 特にwindowsローカル環境下で0.1.9が安定して動作したため、その手順を解説します。(1.1)
- 一方、google coloboでは0.1.9版は不安定でバージョンエラーが多いため、依然として0.1.6の記述を残しています。(1.2)
0. 始めに
ご覧の読者の方はすでにマーケティング・ミックス・モデリング(Marketing Mix Modeling(MMM))についてはご存知かと思います。MMMの簡単な概念などはこちらを参照ください。
さて本稿ではMMMツールの1つであるgoogleのLightweightMMM1Duque, P., Nachbar, D., Abe, Y., Ahlheim, C., Anderson, M., Sun, Y., Goldstein, O., & Eck, T. (2022). LightweightMMM: Lightweight (Bayesian) Marketing Mix Modeling (Version 0.1.6). Retrieved from https://github.com/google/lightweight_mmmの使い方などを解説したいと思います。このツールはpythonベースで作成されており、numpyroと言われるjaxをバックエンドとする確率言語ライブラリを用いた計算を行います。
以前はwindowsローカル環境下では上手く動かなかったのですが、0.1.9版になってローカル環境下(ただしanaconda)でも安定して動くようになりました。 先にとりあえず動かしたいという方むけに実践(1章)を、その後に細かなモデル式やRobynとの違いなどの解説(2章)を行います。 実践は1.1でwindowsマシン環境下での、1.2でgoogle colobo上での設定と手順を解説し、1.3以降で両者共通の実行方法を解説します。
jaxはバージョンの依存性でエラーが起こりやすいため、google colabo上での実行を推奨します。特にwindowsではjaxのサポートが限定的2https://github.com/google/jax/issues/438なため上手くいかないことが多いようです。一応最後にwindows環境で動かすための処方箋を記述します。さらに
google colaboでは0.1.9版で実行すると現在(2023年1月時点)エラーが出ます。そのため0.1.6版の手順を示します。
同じような機能をもつRobynと比較しながら解説できればと思います。情報は十分吟味しておりますが間違いや不適切な表現ございましたらお手数ですがご指摘頂ければ幸いです。
参考にしたサイト
- 公式 doc https://lightweight-mmm.readthedocs.io/en/latest/index.htm
- github https://github.com/google/lightweight_mmm
- 元の論文 Jin, Y., Wang, Y., Sun, Y., Chan, D., & Koehler, J. (2017). Bayesian Methods for Media Mix Modeling with Carryover and Shape Effects. Google Inc. https://storage.googleapis.com/pub-tools-public-publication-data/pdf/b20467a5c27b86c08cceed56fc72ceadb875184a.pdf
- youtubeでの実践動画 https://www.youtube.com/watch?v=pruAeMBHi5M
1. 実践
1.1 windows anaconda環境下での実行
使用するデータやプログラムなどはここにおいてあります。 0.1.9という名前が入っているpgmを参考にしてください。またanacondaのインストールなどの方法はここでは割愛します。
環境準備
conda create --name [任意の環境名]
conda activate [任意の環境名]
conda install pipライブラリインストール
numpyやpandasなどの基本的なライブラリをインストールします。当方の環境と同じにする場合ここにある「requirements.txt」をDLし、anaconda作業フォルダにおいて以下のように入力してください。筆者と同じバージョンのライブラリがインストールされます。
pip install -r requirements.txtlightweight-MMMのインストール
pip install lightweight-mmm==0.1.9jupyterのインストールと起動
pip install jupyter
jupyter notebookこれ以降はjupyter notebook上で実行してください。
必要ライブラリのimport
# Import jax.numpy and any other library we might need.
import jax.numpy as jnp
import numpyro
import pandas as pd
import numpy as np# Import the relevant modules of the library
from lightweight_mmm import lightweight_mmm
from lightweight_mmm import optimize_media
from lightweight_mmm import plot
from lightweight_mmm import preprocessing
from lightweight_mmm import utils
# seed値の設定
SEED = 1
N_CHAINS = 2
numpyro.set_host_device_count(N_CHAINS)あとはgoogle coloboと同じ(1.3以降参照)です。
1.2 google colobo上での実行
使用するデータやプログラムなどはここにおいてあります。以降は全てgoogle colabo上で実行しています。
google driveをマウント
import os
from google.colab import drive
drive.mount('/content/drive')os.chdir('/content/drive/MyDrive/003_Project/901_MMM(Stats)/google light MMM')
os.getcwd()ライブラリのインストール
2023年1月に最新の0.1.7がリリースされていますが、これがgoogle colaboの環境と相性が悪いため0.1.6を使用します。またmatplotlibのバージョンも適したものにしておきます3これがないとplotでエラーが出ます
# lightweight_mmmのインストール
!pip install lightweight_mmm==0.1.6 # 2023年1月追加
# matplotlib
!pip uninstall -y matplotlib
!pip install matplotlib==3.1.3
2023/02/27追記) 2/17よりjaxがバージョンアップされたため(0.4.4に)colabo上で行うには、lightweightMMMインストール後に
!pip uninstall -y jax !pip install jax==0.4.2 !pip uninstall -y jaxlib !pip install jaxlib==0.4.2
と入力し、0.4.2 (or 0.4.3)版のjaxとjaxlibをインストールする必要があります。これがないとレスポンスカーブのプロットでエラーがでます。
後はimportします。
# import numpy as np
import jax.numpy as jnp
import numpyro
import pandas as pd# Import the relevant modules of the library
from lightweight_mmm import lightweight_mmm
from lightweight_mmm import optimize_media
from lightweight_mmm import plot
from lightweight_mmm import preprocessing
from lightweight_mmm import utils
# seed値の設定
SEED = 1
N_CHAINS = 2
numpyro.set_host_device_count(N_CHAINS)1.3 windowsローカル/google colaboratory 共通手順
データの入力・加工
データ読込
# rawデータ読み込み
df = pd.read_csv('data.csv')
print (df.head())
# 2020までを学習データにするためindex取得
print (df[df['Date']<='2020-12-31'].index.max())データ準備
# メディア投下量
media_data = jnp.array(df.loc[:,['TV','Radio','Banners']])
# メディア以外の特徴量
# extra_features = jnp.array(df.loc[:,['平均気温','降水量','週末FLG']])
# 売上
target = jnp.array(df.loc[:,'Sales'])
# Total Cost 各メディアの投下金額
costs = media_data.sum(axis=0) # media_dataがimpの(imp / 1000) * CPMなどと変換訓練・検証に分ける
# 訓練検証に分ける
split_point = 155 + 1 # 2020までを訓練データとする 分割部分のindexを与える
# Media data
media_data_train = media_data[:split_point, ...]
media_data_test = media_data[split_point:, ...]
# Extra features # 今回はその他変数なし
# extra_features_train = extra_features[:split_point, ...]
# extra_features_test = extra_features[split_point:, ...]
# Target
target_train = target[:split_point]
target_test = target[split_point:]スケーリングする
# スケーリングする 平行移動ではなく、平均を1とする変換
media_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
# extra_features_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
target_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
cost_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
media_data_train_scale = media_scaler.fit_transform(media_data_train)
# extra_features_train_scale = extra_features_scaler.fit_transform(extra_features_train)
target_train_scale = target_scaler.fit_transform(target_train)
costs_scale = cost_scaler.fit_transform(costs)モデリング
# modelのインスタンス化 メディアの減衰効果をcarryoverにする
mmm = lightweight_mmm.LightweightMMM(model_name="carryover") model_nameはhill_adstock/adstock/carryover から選択可能です。
%%time
number_warmup=2000
number_samples=2000
# For replicability in terms of random number generation in sampling
# reuse the same seed for different trainings.
mmm.fit(
media=media_data_train_scale,
media_prior=costs_scale,
target=target_train_scale,
# extra_features=extra_features_train,
number_warmup=number_warmup,
number_samples=number_samples,
number_chains=N_CHAINS,
seasonality_frequency=52,# 日次データの場合365として以下の変数のコメントアウトをはずす
# weekday_seasonality=True,
seed=SEED)出力確認
パラメータの統計量
# 推定パラメータの統計量確認
mmm.print_summary()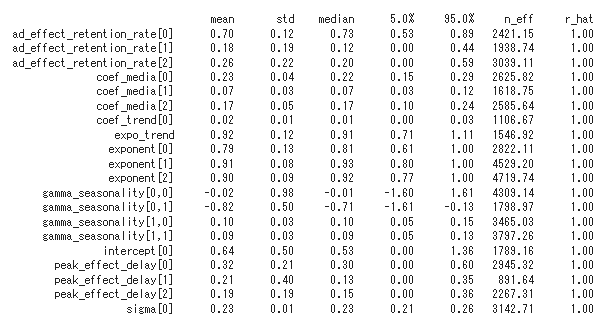
解説の章で説明しますが、lightweightMMMはパラメータを点推定(つまりたった一つの推定値を返す)するのではなく、パラメータの事後分布からのサンプリングを返します(このプログラムでは4000個返しています)。上記のテーブルは表側にパラメータ名が、表頭にその4000個の平均(mean)や標準偏差(std)、中央値(median)などが記されてます。
上から4行目~6行目のcoef_mediaの3つが対応するメディアの重みです。詳細は以下です。
全てのモデル共通
- intercept(α):ベースライン
- coef_media(βm):メディアの重み(m)
- coef_trend(μ) / expo_trend(k):μt^k (トレンド)
- Γij : 周期、j=1の場合年次トレンドの強さ、j=2の半期トレンドの強さ
- coef_extra(λ)i:その他の要素の重み(i)
carry over
- ad_effect_retenshion_ratio(τm):加重平均項 (小さいほど減衰しやすい)
- peak_effect_delay(θm):加重のピーク (0であるのが自然)
- exponent(ρm):指数減衰
adstock
- lag_weight(λm):減衰重み (小さいほど減衰しやすい)翌日にλ倍小さくなる
- exponent(ρm):指数減衰
hill_adstock
- half_ax_effective(Km):半減期の点
- slope(Sm):ヒル関数の冪 (ヒル係数)
- lag_wight(λm):減衰重み (小さいほど減衰しやすい)翌日にλ倍小さくなる
この重みの4000個の分布の収束を確認します。
# 分布の確認
plot.plot_media_channel_posteriors(media_mix_model=mmm)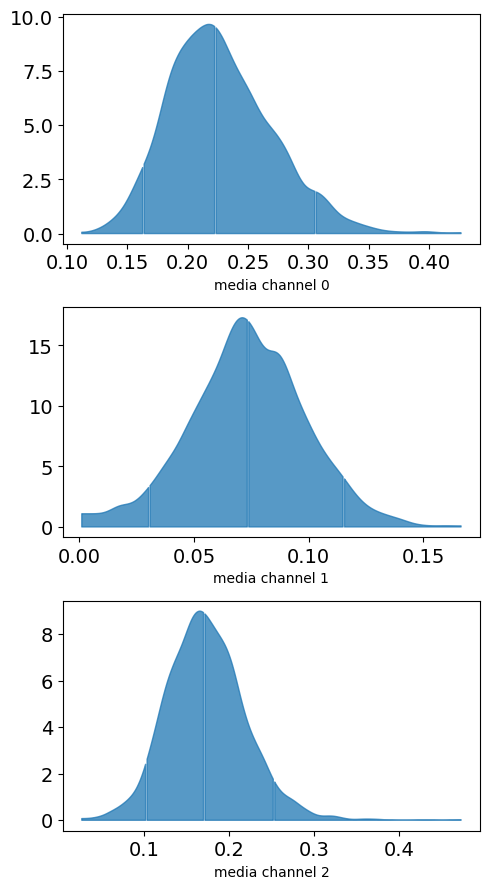
予測値
予測・実績を比較する。まあまあ当てはまり良さそうです。
# scaleある場合
plot.plot_model_fit(mmm, target_scaler=target_scaler)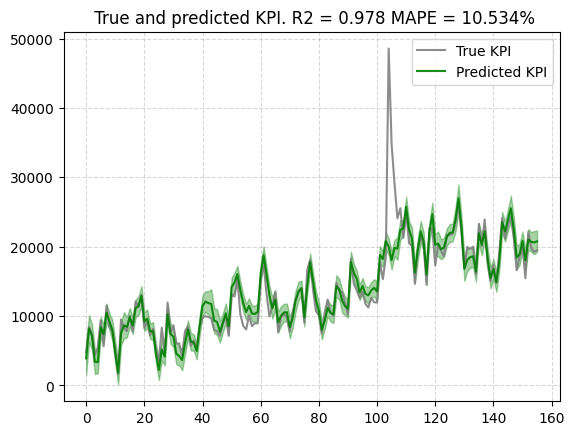
次に検証データに当てはめます。
# testデータに当てはめる
new_predictions = mmm.predict(media=media_scaler.transform(media_data_test),
# extra_features=extra_features_scaler.transform(extra_features_test),
seed=SEED)
# new_predictions.shape
# plotする
plot.plot_out_of_sample_model_fit(out_of_sample_predictions=new_predictions,
out_of_sample_target=target_scaler.transform(target_test) )
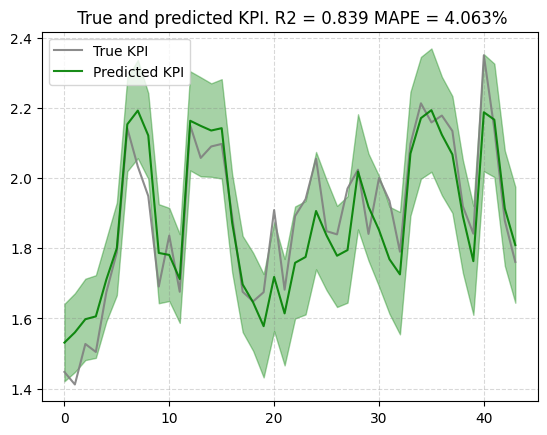
その他出力
# 推定値などを出力
media_contribution, roi_hat = mmm.get_posterior_metrics(target_scaler=target_scaler, cost_scaler=cost_scaler)# 貢献度の可視化
plot.plot_media_baseline_contribution_area_plot(media_mix_model=mmm,
target_scaler=target_scaler,
fig_size=(30,10))
ROIを可視化します
# ROI可視化
plot.plot_bars_media_metrics(metric=roi_hat, metric_name="ROI hat")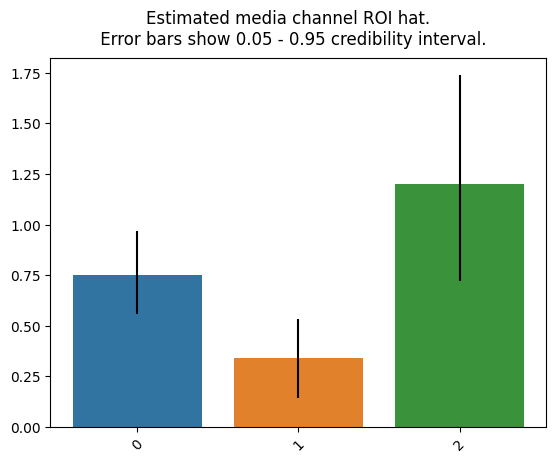
引数にチャンネル名を入れることでグラフのラベルとしてチャンネル名を表示できます。上図では左から「TV」「Radio」「Banners」です。ROIの大きさはBanners>TV>Radioです。Robynで計算した場合も同じ順番になります。
最後にsaturationカーブをプロットします。
# メディア投下量と売上の関係
plot.plot_response_curves(
media_mix_model=mmm, target_scaler=target_scaler, seed=SEED)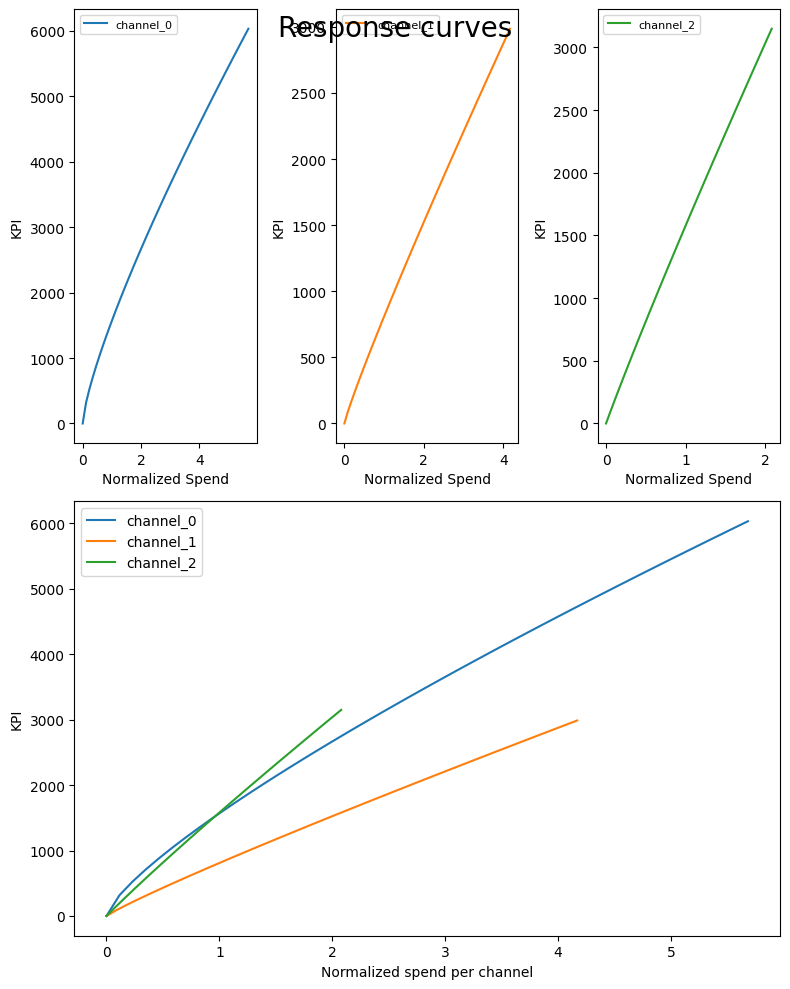
channnel_0-2はそれぞれ「TV」「Radio」「Banners」に対応しています。
予算最適化
# 成果変数の円/成果の単位を入力→売上円であるため、全部1でOK
prices = jnp.ones(mmm.n_media_channels)最適化したい期間は訓練データの直後から向こう44週分とします。予算の総量は訓練データの各メディアの週次(日次のデータの場合日次)平均*44です。但し平均をとるときに出稿額が0円の週(日)も分母に入れていることに注意してください。Robynは0円の週(日)を分母に含んでいないため、最適化前のメディアの構成比率がlightweightMMMと異なります。
# 最適化したい期間
n_time_periods = media_data_test.shape[0]
print (n_time_periods)
# 予算の総量
budget = jnp.sum(media_data_train.mean(axis=0)) * n_time_periods
print (budget)
# Run optimization with the parameters of choice.
solution, kpi_without_optim, previous_media_allocation = optimize_media.find_optimal_budgets(
n_time_periods=n_time_periods,
media_mix_model=mmm,
# extra_features=extra_features_scaler.transform(extra_features_test)[:n_time_periods],
budget=budget,
prices=prices,
media_scaler=media_scaler,
target_scaler=target_scaler,
seed=SEED)最適解取り出します。
# Obtain the optimal weekly allocation.
optimal_buget_allocation = prices * solution.x
optimal_buget_allocation
アロケーション前の予算配分を取り出します。
# similar renormalization to get previous budget allocation
previous_budget_allocation = prices * previous_media_allocation
previous_budget_allocation# 最適化前後の予算配分比率をプロット
plot.plot_pre_post_budget_allocation_comparison(media_mix_model=mmm,
kpi_with_optim=solution['fun'],
kpi_without_optim=kpi_without_optim,
optimal_buget_allocation=optimal_buget_allocation,
previous_budget_allocation=previous_budget_allocation,
figure_size=(10,10))
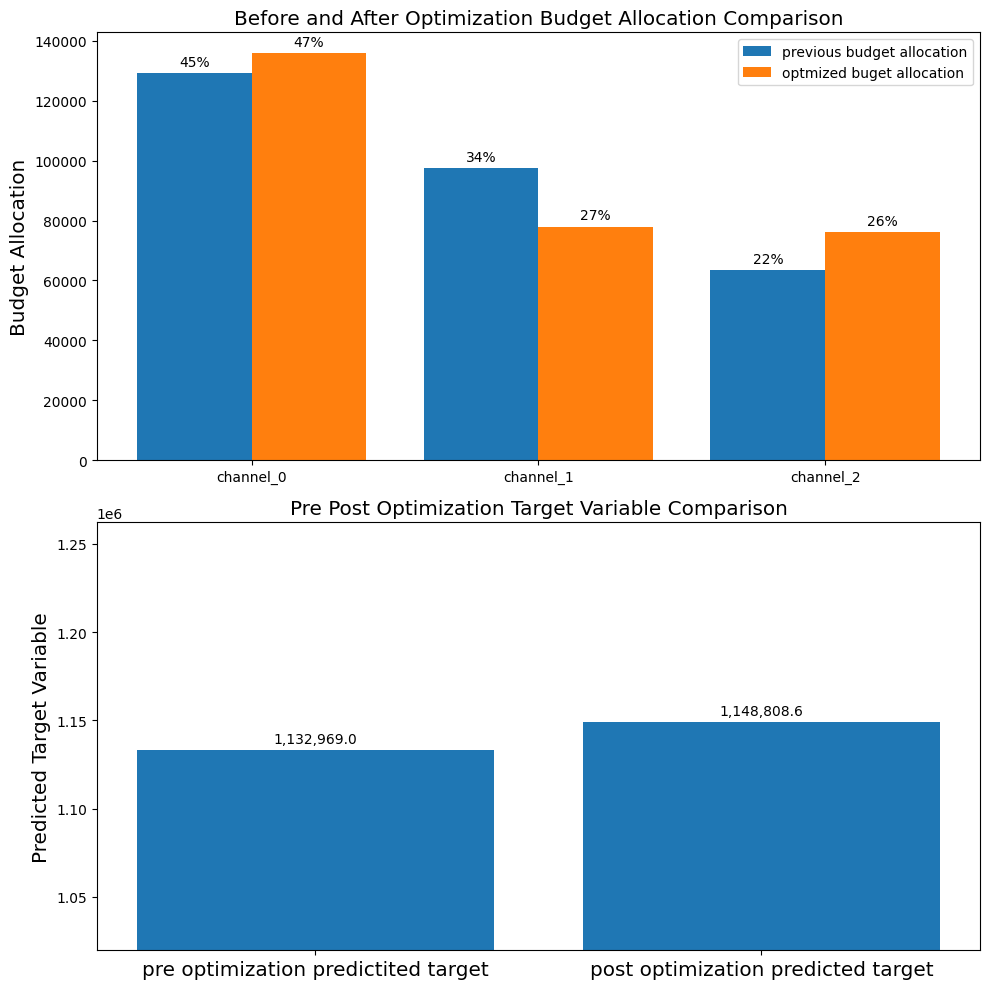
最適化前後であまり比率が変わっていないように見えます。これは内部的に元の比率からの変化率を制御するパラメータがあり、デフォルトではこれが0.2になっているため、あまり変化がなかったと考えられます。bounds_upper_pct / bounds_lowwer_pct というパラメータに数値を与えることで増加率 / 減少率の制約を変えることができます。
2. 解説
細かい説明はこの方のブログ (TJO氏)か、元の論文を参照願います。
モデル
lightweightMMM(lw3m)のモデルは「メディア投下量変数」、「その他の成果に影響を与える変数」、「季節性」、「周期性」、「ベースライン」を説明変数とし、成果を目的とする一般化加法(のような)モデルです。
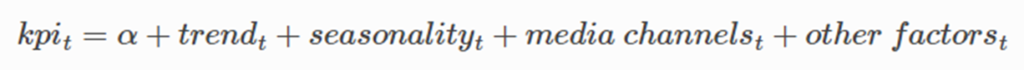
ほぼRobynの構成要素と同じですが、Robynは祝日を簡単にモデリングする機能があります。lw3mで祝日を変数として入力したい場合はその他変数として定義する必要があります。
変数変換
広告の減衰効果、逓減効果を表現するためにメディア投下量を変数変換します。
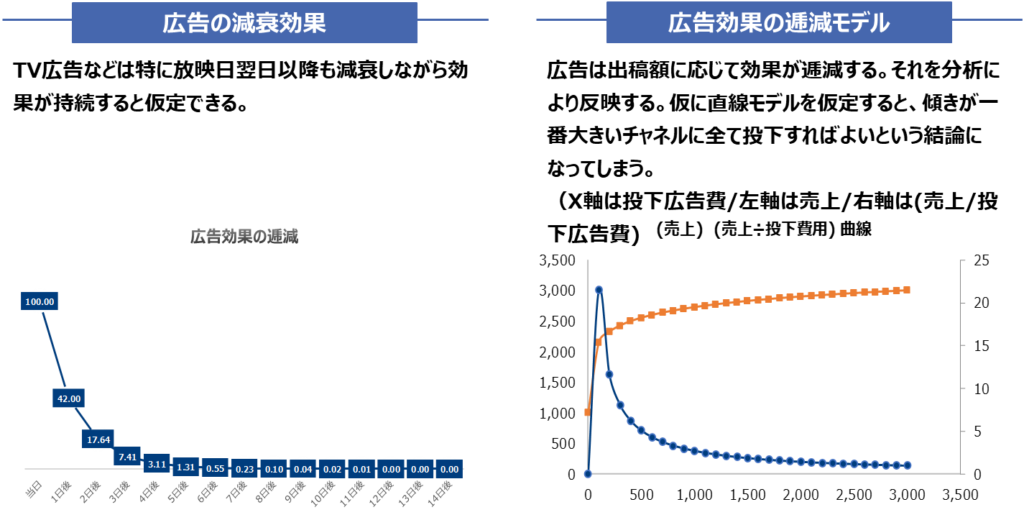
Robynでは減衰効果の形状を幾何型Adsctockとワイブル型Adstockの2つから選択するのに対して、lw3mは「adstock」「carryover」「 hill_stock」の3つから選びます。それぞれの特徴は以下の通りです。hill_stockはRobynの幾何型Adstockに似ています。
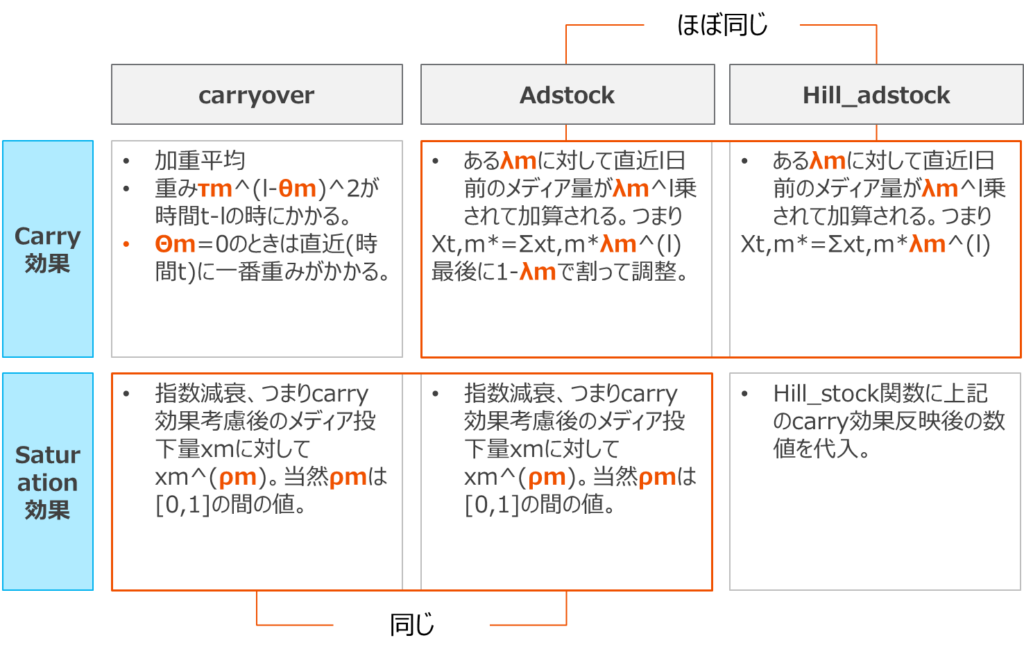
Adstockという言葉は一般的にはこの減衰効果を指す場合が多いのですが(一方で逓減効果はsaturaiton)、文脈によっては減衰、逓減効果双方を合わせた概念として言及される場合もありますので注意が必要です。4wiki https://en.wikipedia.org/wiki/Advertising_adstock
周期・トレンド
周期は複数の周期成分を持つ三角関数の合成和で記述します。この仕様はRobynとほぼ同じです。デフォルトでは1番大きな周期(つまり三角関数の引数の分母)は52となっています。これは週次データの使用が想定されているから(52週=365日)です。日次データの場合、引数で365と指定します。
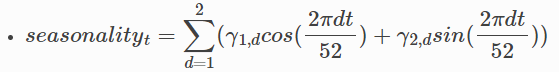
トレンド成分は指数部分を持つ関数です。Robynと異なるのはトレンドの転換に弱いということです。
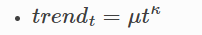
パラメータ推定
それぞれの変数の重みパラメータと変数変換のパラメータを推定します。推定したいパラメータを、それぞれに設定した事前分布とデータから得られる尤度を用いて、それらの事後分布からサンプリングします(このアルゴリズムをMarkov chain Monte Carlo (MCMC)と呼びます)。
サンプリングのため一つの推定量を決めたい場合は、その平均値や中央値を使用します(点推定するのではなく分布として扱うのがベイズ統計の特徴であるため、これはあまり推奨はされない)。
Robynとの違いは事前分布に経験則から分かる分布を設定することで、少ないデータでも推定が可能になることです(多分)。余談ですがベイズ回帰のパラメータ推定において、ある特殊な場合に限って事後分布が最大となるパラメータの点を求めることとリッジ正則化項付きの誤差を最小にすることは等価となります(PRML 第3章)。従ってある意味では双方のツールとも同じようなことをやっているとも言えます。
予算最適化
MMMの最後の仕事は構築されたモデルを用いて、予算の最適化を行うことです。lw3mは予算上限と出稿期間を指定することで、その期間で成果が最大になる予算編成を返します。
デフォルトでは学習データの終了日次から指定した期間の最適化をしますが、media_gapという引数に[x]と指定することで学習データの終了日次からx期間後を始点とし、そこから指定された期間の最適化をします。
無料相談大歓迎です。ご興味ございましたら、お問い合わせはこちらから宜しくお願い致します。