実践編が物足りないとの声を頂いたのでPythonで実際にMMMを実行する方法をご紹介したいと思います。
まず復習ですがMMMは広告効果の定量化で、数学的には広告投下コスト変数X1-Xnを入力とし出力をセールス変数とする関数F(X1,X2,X3,,,Xn)をヒストリカルデータから推定する事でした。
本稿で使用したデータとjupyter Notebookは
Github上で公開してあります。必要なデータは適宜
ここからDLして下さい。
入力データ
前回述べましたが、時系列で投下コストと対応するセールス変数のデータが必要です。一方企業秘密に近い情報なのでweb上で適当なデータを拾ってくるという事は出来ないので、それっぽいデータを自分で作成しました。
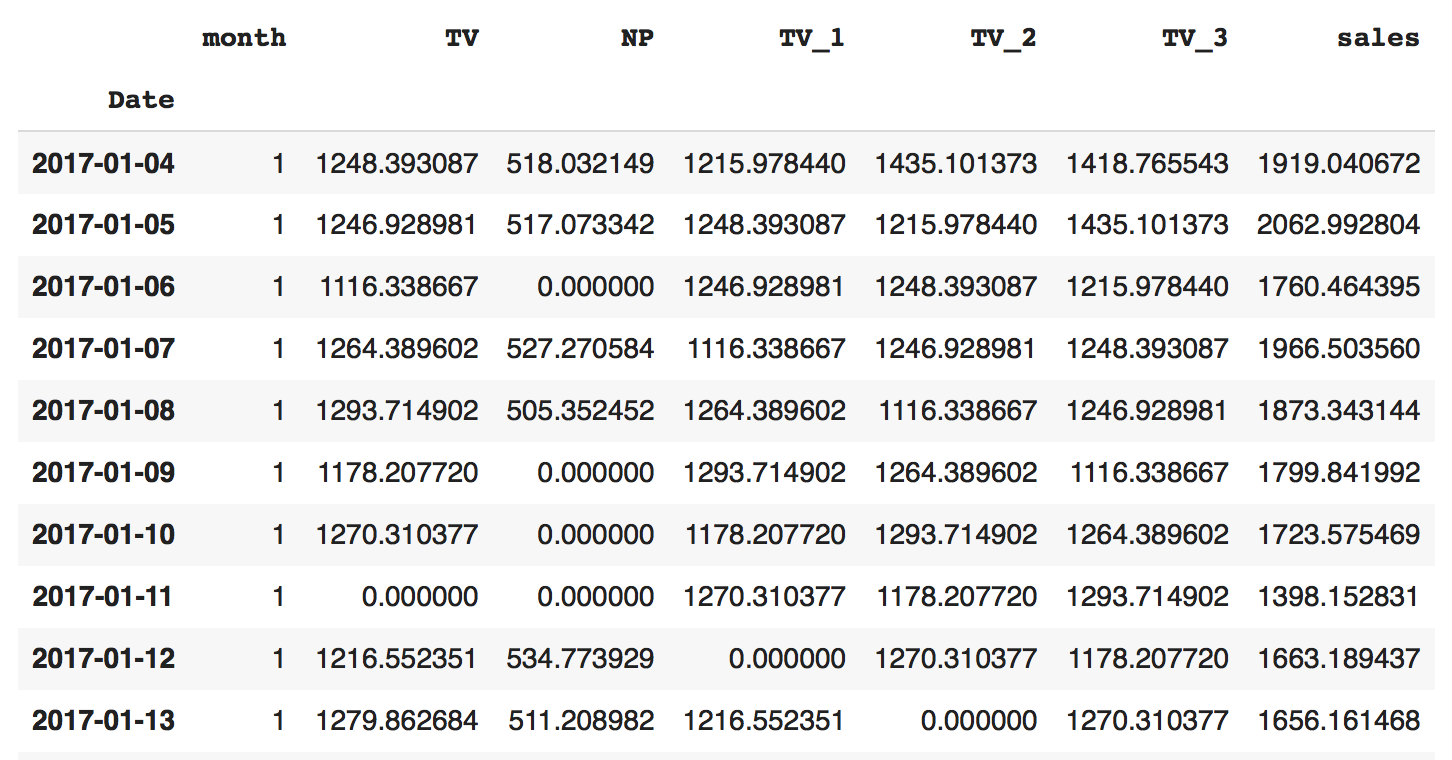
TV:=当該日のTV投下コスト TV_n:=当該日n日前のTV投下コスト(この例ですとn=1,2,3), NP:=当該日の新聞投下コスト、monthは月ですがここでは使いません。単位は適当に(千円)と解釈頂いて結構です。
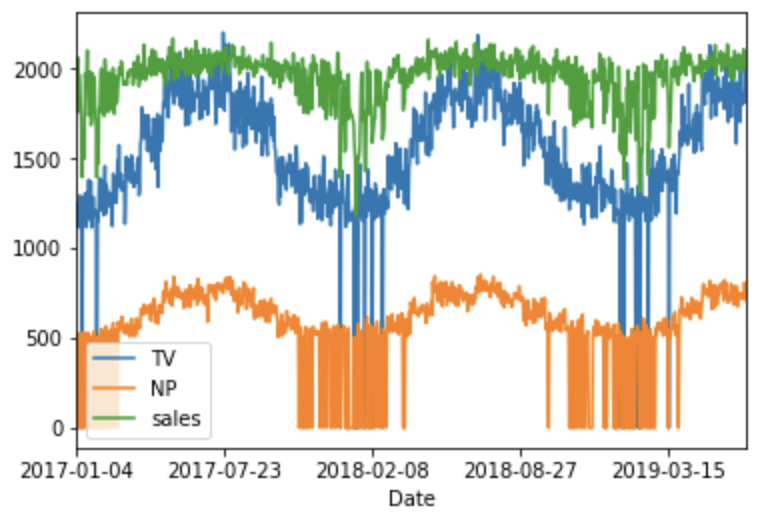
時系列は以下です。0の部分が少々極端です。
モデル構造の決定
分布からモデル構造の仮説立てを行います。salesと他の変数の関係は以下の様になりました。
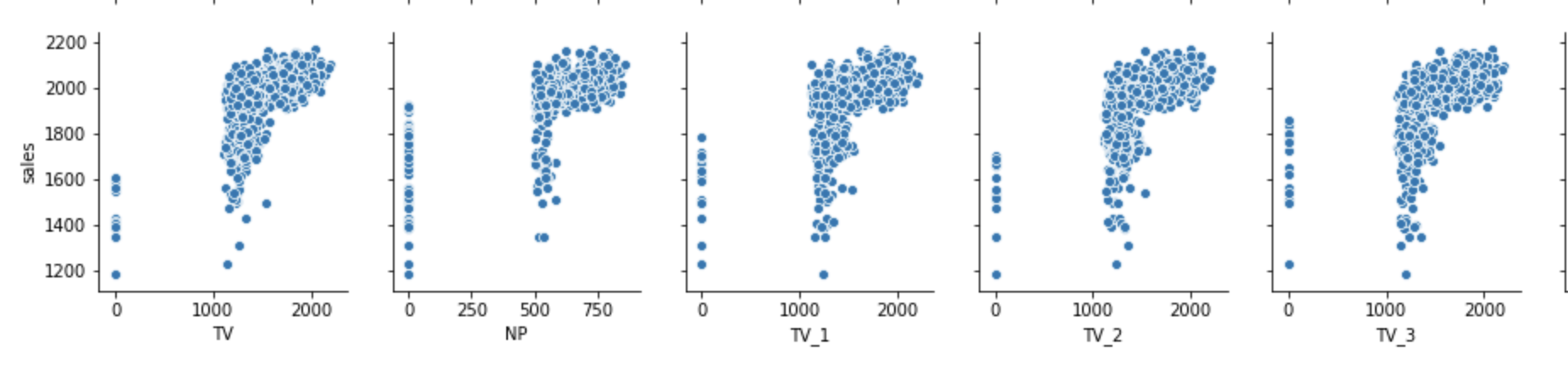
いずれの変数も投下量とsalesは比例している様に見えます。一方で回帰直線を当てはめるには以下の点で不適切と考えます。
- logの様な逓減効果を表現できていない(図を見るとlogの方が適切に見える)
- 直線モデリングをしてしまうと、「予算最適化の時に傾きが一番急なチャネルに全部投下する」という極端な意思決定をしてしまう。
ですので
y=log(X)の様な形を想定するとします(仮説①)。次にTV_1,TV_2,TV_3の変数は減衰しながら翌日以降のsalesにも影響を与えかつ、その減衰はλ^(n)(0<λ<1)で表現されるとします(仮説②)。
従ってモデルは
$$sales=\beta_{0}+\beta_{1}(log(TV+1)+log(\lambda TV_1+1)+ \\ log(\lambda^2 TV_2+1)+log(\lambda^3 TV_1+1))+\beta_{2}log(NP+1)$$
です。
パラメータ推定
前回も同じことを述べましたが、上記式に対して通常のRやPythonの回帰モデルを当てはめる事はできません。また最小二乗法を行うとしても、λの項が3乗であるため初期値によっては適切な解が得られない場合があります。
そこでMCMCを用いてパラメータを推定します。
#説明変数と目的変数整理
X = df[['TV','NP','TV_1','TV_2','TV_3']]
y = df['sales']
#pystanの準備
model = """
data {
int<lower=0> N;
vector[N] TV;
vector[N] TV_1;
vector[N] TV_2;
vector[N] TV_3;
vector[N] NP;
vector[N] y;
}
parameters {
real beta_0;
real beta_1;
real beta_2;
real<lower=0, upper=1> lambda;
real<lower=0> sigma;
}
model {
for (i in 1:N)
y[i] ~ normal(beta_0 + beta_1 * (log(TV[i]+1)+log(lambda * TV_1[i]+1)+log(lambda^(2) * TV_2[i]+1)+log(lambda^(3) * TV_3[i]+1)) +log( NP[i]+1)* beta_2 , sigma);
}
"""
#pystanに食わせるデータ定義(辞書型)
dat = {'N':len(X), 'TV': X['TV'].values,'TV_1': X['TV_1'].values,'TV_2': X['TV_2'].values,'TV_3': X['TV_3'].values,'NP': X['NP'].values, 'y': y.values}
#MCMC実行
fit = pystan.stan(model_code=model, data=dat)
これを実行すると、

という結果が得られます。色々難しい事を述べる事は可能ですが、ここではサンプルされたパラメータの平均(上の図の一番左の項目)を用いてモデル結果を記述します。
param = fit.get_posterior_mean().mean(axis=1)
#当てはめ
df['predict'] = param[0]+param[1]*(np.log(df['TV']+1)+np.log(param[3]*df['TV_1']+1)+
+np.log(param[3]**(2)*df['TV_2']+1)+np.log(param[3]**(3)*df['TV_3']+1))+param[2]*np.log(df['NP']+1)
#答えと比較
df[['sales','predict']].sort_index().plot()
*但しシードを固定していないためやる度に微妙に変わります。
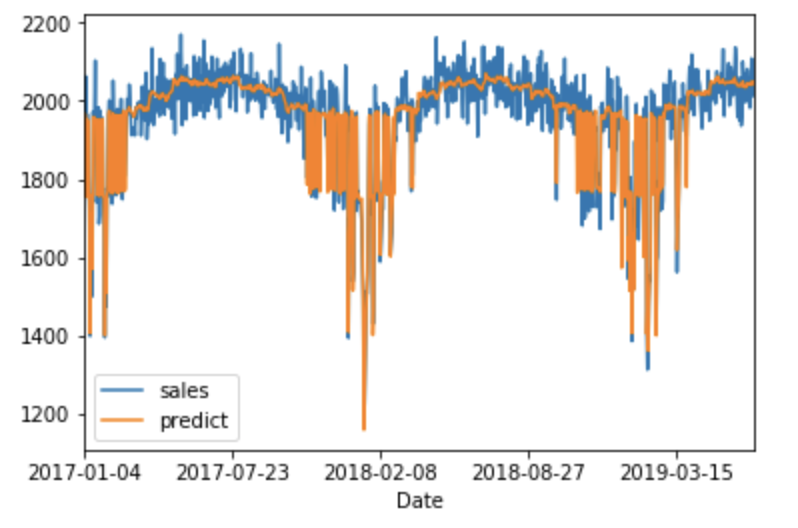
上記の様になりまあまあの当てはまりではないでしょうか?
githubのipynbファイルをご覧になると分かりますが、今回は自分で生成させたデータを使っていますので答えを知っているとも言えます。実際はグラフを眺めながらどの様な構造を背景に持つか吟味しながら適切なモデルに当てはめて行きます。
Author Profile
-
株式会社Crosstab 代表取締役 漆畑充
-
2007年より金融機関向けデータ分析業務に従事。与信及びカードローンのマーケテイングに関する数理モデルを作成。その後大手ネット広告会社にてアドテクノロジーに関するデータ解析を行う。またクライアントに対してデータ分析支援及び提言/コンサルティング業務を行う。統計モデルの作成及び特にビジネスアウトプットを重視した分析が得意領域である。統計検定1級。
技術・研究のこと:qiita
その他の個人的興味:note
お問い合わせは株式会社Crosstabまでお願いいたします