
[想定している読者像]
- お客様から広告効果を問われている広告代理店のプランナーの方。
- 代理店レポートではなく自社で広告効果を検証したい、広告主のマーケテイングマネージャー、ブランドマネージャーの方。
- Robyn MMMを実際に動かしてみたいデータアナリストの方。
[コンテンツ属性]
ビジネス:★★★☆☆
データアナリティクス:★★★★★
エンジニアリング:★☆☆☆☆
Meta(旧Facebook)社の開発したAutomated Marketing Mix Modeling (MMM)ツールの一つRobynの紹介と実践をします。
補足
更新履歴
2024年8月22日更新
- Robynのバージョンが3.11系になり、日本の祝日が使えるようになっため、それに対応したコードに書き換え。
- Windowsで実行する場合の設定の部分の解説を追加。
- その他遭遇したエラーについて、内容と対策(という名の対症療法)を追記。
- 不明瞭な記述の修正。
2023年7月更新
- Robynのバージョンが3.10系になったことで、内容を更新しました。
- 一部の関数の引数及び挙動が変更になっており、更新前の情報では動かない箇所があります。
実行環境など
抜け漏れなく記述できているかは分かりかねますが、大体以下の設定でやっております。
macOS
- R 4.3.1
- Robyn 3.11.1
- reticulate 1.37.0
- nevergrad 1.0.4
- Python 3.9.7
どのPythonを使用するかを指定しない場合、reticulateが自動的にインストール済みのものを使用します。私の場合、事前にインストールしていたAnacondaのlibpython.dylibが選択されていました。この選択に失敗すると、nevergradの実行—つまりモデルの実行—でエラーが発生します。このような場合、Pythonを再ダウンロードして再設定すると、問題が解決する可能性があります。
windows
- R 4.4.1
- Robyn 3.11.1
- reticulate 1.38.0
- nevergrad 1.0.4
- Python 3.11.8
Rとpythonをインストールしなおしたので最新になっていますが、それ以外はmacと同じです。
良くあるエラー
nevergradがない① (macで発生) Robyn ver 3.10.3
Error in robyn_mmm(hyper_collect = InputCollect$hyperparameters, InputCollect = InputCollect, :
You must have nevergrad python library installed.RのversionがM1/M2チップ用を使用していると、出る可能性あり。「R-4.3.1-x86_64.pkg」を使用すれば多分出ない。
nevergradがない②
win/mac問わず以下のメッセージが出た場合、reticulateがPythonを掴むのを失敗している可能性があります。
Error in robyn_mmm(hyper_collect = InputCollect$hyperparameters, InputCollect = InputCollect, :
You must have nevergrad python library installed.py_config()でエラーが出る場合はおそらく、その可能性が高いです。pythonを公式サイトからダウンロード、インストールしなおします。
モデル構築時に以下のエラー
Running trial 1 of 5 | | 0%Timing stopped at: 0 0 0 signif(nevergrad_hp_val[[co]][index], 10) でエラー: 数学関数に数値でない引数が渡されましたと出る場合。
robyn とreticulate が異なるバージョンのRで作成されているかどうかを確認してください。もしそうであれば、Rを再インストールすると治るかもしれません。
1. MMMの復習
以前こちらでMMMについて扱いました。改めて復習をします。
MMMはマーケティングの費用対効果を定量化する手法の総称とされています。具体的には収益に与える各メディアの効果、それ以外の効果をそれぞれ定量化するなどです。下図はMMMのイメージです。Robynの公式HPより引用しています。
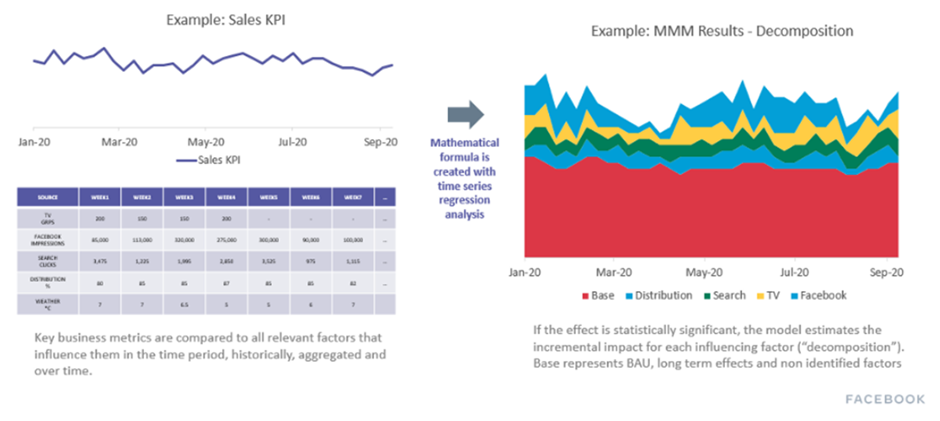
MMMの実践は複数のステップからなります1https://facebookexperimental.github.io/Robyn/docs/analysts-guide-to-MMMhttps://github.com/google/lightweight_mmmなどを参考に筆者作成。

MMMでは成果変数(売上やコンバージョンなど)への寄与要因を以下のように仮定しています。
| 第項目 | 項目 |
|---|---|
| ペイドメディア | 4マス(TV/ラジオ新聞/雑誌) |
| ネット広告(google/Yahoo) | |
| SNS(Facebook/Twitter/Instagram) | |
| 非ペイドメディア | オウンドメディア |
| プレスリリース | |
| SNSでの発信 | |
| イベント変数 | キャンペーンなど |
| 競合キャンペーン | |
| スポーツや音楽イベントなど | |
| ベースライン | トレンド |
| 季節性 | |
| 祝休日 | |
| 気候情報 |
以下は入力データの一例です。
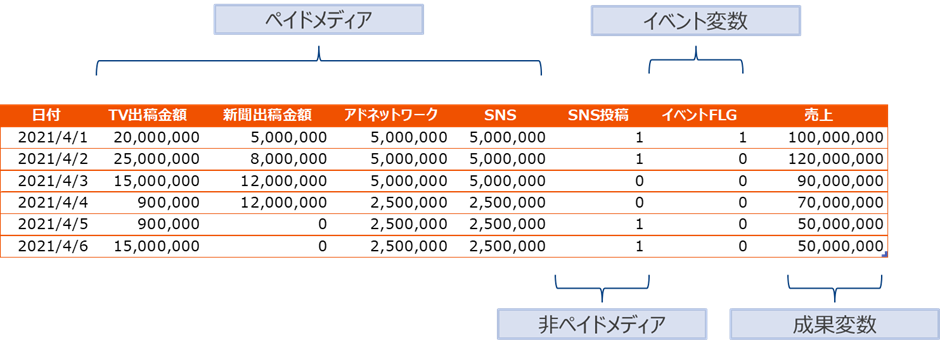
2. Robyn実践
RobynはMeta(Facebook)のメンバーが作成した自動MMMツールです。本稿では簡単なデータを用いて広告効果の定量化と予算の最適化を実践していきます。色々な機能がありますが、今回は上記に必要な機能に絞って解説します。また余裕があれば別記事でオプション機能の紹介をしたいと思います。なお本実践は主に、meta公式チュートリアルを参考にしています。
WordPressの仕様でRの代入[<-]記号が[<-]に化けてしまっています。読み替えをお願いします。
ここで使用するデータとコードはhttps://github.com/mitsu666/Robyn_demo からDLできます。
2.1 Rをインストール
この手のライブラリでは珍しく、ラッパーがRしかないとのこと。Rの最新版をここからDLしてインストール。
2.2 Robynのインストールとそれに必要な準備
まず作業ディレクトリ(ここでは./MMM_01を作成しそこを作業ディレクトリとした)に対象となるデータを置いておきます。次に以下のコードをRのコンソール(またはRstudio)2RのIDE、ほとんどのRユーザが使用しているため、ここでも推奨。https://www.rstudio.com/products/rstudio/ 上から入力し実行していきます。
################################################################
#### Step 0: Setup Environment
# 作業ディレクトリの設定
setwd("./dev/MMM_04")
# 必要なパッケージのインストール(初回のみ実行)
# Robyn: マーケティングミックスモデリング用
# reticulate: Pythonとの連携用
install.packages("Robyn")
install.packages("reticulate")
# ライブラリの読み込み
library(reticulate)
library(Robyn)
# Robynのバージョン確認
packageVersion("Robyn")Robynはモデリングに際してNevergra3gradient-freeオプティマイザー、つまり導関数を必要としない最適化ソルバー。https://facebookresearch.github.io/nevergrad/という最適化のソルバーを使用します。そのためにRからPythonを使用できるようにしておきます。Pythonを使用するためにはreticulate4reticulate https://techblog.nhn-techorus.com/archives/8329というライブラリを使います。
nevergradを実行するpython環境を作成します。
# Python環境の設定 (virtualenvを使用)
virtualenv_create("r-reticulate")
use_virtualenv("r-reticulate", required = TRUE)
# Python用パッケージのインストール
py_install("nevergrad", pip = TRUE)
# Pythonのパス設定
use_python("~/.virtualenvs/r-reticulate/bin/python")
# reticulateの設定確認(オプション)
# PythonとRの接続が正しく行われているか確認する場合に使用
# reticulate::py_config()
# ファイルの作成設定
# FALSEにするとローカルファイルを作成せず、メモリ内で処理
create_files <- TRUE
# 結果を格納するフォルダを指定
# 事前にカレントディレクトリ内に"results"フォルダを作成しておく必要があります。
# ./resultsフォルダを作成する(存在しない場合)
if (!dir.exists("./results")) {
dir.create("./results")
}
robyn_directory <- "./results"use_pythonの引数にはpythonの実行ファイルがある場所を指定します。
- Windowsの場合:「C:/Users/[あなたのユーザ名]/R_work/.virtualenvs/r-reticulate/Scripts/python.exe」
- macの場合:「~/.virtualenvs/r-reticulate/bin/python」
にあるはずです。Windowsとmacの違いはここの設定ぐらいです。あとは同じです。
2.3 入力データ
入力データは、筆者が以前書籍5https://www.amazon.co.jp/dp/B098HZ9KXG/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1執筆用に用意したデータを用います。人工的に作成した広告の投下費用や売上などからなる日次の時系列データです。
| 変数 | 内容 | 仮説 |
|---|---|---|
| 日付 | 日時 | – |
| ネット広告出稿金額 | その日のネット広告出稿金額 | 売上に比例 |
| TV広告出稿金額 | その日のTV広告出稿金額 | 売上に比例 |
| 平均気温 | その日の平均気温 | 売上に比例 |
| 降水量 | その日の降水量 | 売上に反比例 |
| 売上金額 | その日の売上げ | – |
| 週末FLG | 週末であるならば1それ以外0の変数 | 1の場合売上増加 |
2.4 データ読み込み
################################################################
#### Step 1: Load data
# サンプルの入力データをCSVファイルから読み込みます。
dt_simulated = read.csv(file='sample.csv')
# 日本語の変数名は、プロットする際に文字化けする可能性があるため、英字(半角アルファベット)に変換します。
dt_simulated = dplyr::select(
dt_simulated,
datetime = 1,
Net.Spend = 2,
Tv.Spend = 3,
temperature = 4,
rain = 5,
revenue = 6,
Weekend.FLG = 7,
dplyr::everything()
)
# 変換後のデータの先頭部分を確認
head(dt_simulated)2.5 input定義
2.5.1 入力変数指定
################################################################
#### Step 2a: 初回ユーザー向けモデル仕様設定(4ステップ)
#### 2a-1: 入力変数の指定
# メディアとオーガニック変数の係数は正の値になるよう設定
# その他の変数は正負どちらの符号も許容し、カスタマイズ可能
# 入力データを設定
InputCollect <- robyn_inputs(
dt_input = dt_simulated, # 元データ
dt_holidays = dt_prophet_holidays, # 祝日データ
date_var = "datetime", # 日付変数(例: "2020-01-01")
dep_var = "revenue", # 従属変数(売上高やCVなど)
dep_var_type = "revenue", # 従属変数のタイプ(売上高かCVフラグか)
prophet_vars = c("trend", "season", "holiday"), # 時系列要素 ("trend", "season", "weekday", "holiday")
prophet_country = "JP", # 国名(日本の祝日はデフォルトで設定されていないため注意)
context_vars = c("temperature", "rain", "Weekend.FLG"), # イベント情報
paid_media_spends = c("Net.Spend", "Tv.Spend"), # メディア支出
paid_media_vars = c("Net.Spend", "Tv.Spend"), # メディア変数(支出または露出指標を使用)
# organic_vars = c("newsletter"), # PRなどの非広告メディア
factor_vars = c("Weekend.FLG"), # 因子変数(イベントなど)
window_start = "2019-04-01", # モデル構築に使用するデータの開始日
window_end = "2020-03-31", # モデル構築に使用するデータの終了日
adstock = "geometric" # Adstock効果の形状
)
print(InputCollect)回帰係数の符号はデフォルトでは
- メディア / オーガニック: 正
- 他の変数: 正負どちらも
paid_media_signs = “negative”のように指定することでカスタマイズ可能です(広告効果が負と言うことですが、そんな仮定が適当かどうかという問題がありますが)。orgnic_signs / context_signsでオーガニック変数や他の変数も指定可能です。
今回行うデータ特有の注意事項
- 今回説明変数にweekendFLGがあるため、prophet_varsでは[weekday]という項目を外している。
日本の祝日がデフォルトでは使用できないため、prophet_varの設定で[holiday]を外している。日本の祝日の使い方は別途で解説するつもりである。- Robyn バージョン3.11から日本の祝日を関数の引数の値として設定可能です。上記コードではJPとして設定しています。
そのほかの細かいinputの細かい定義は公式HPをご参照してください。(どこかで整理するかも)
Prophet6metaが開発した時系列予測フレームワークに関連した変数があることからわかるように、backendとしてProphetを一部使用しているようです。Ptophetについての記事はこちらをご参照ください。
2.5.2 ハイパーパラメータ指定
ハイパーパラメータは広告効果の逓減(saturation)を制御するパラメータとAdstockと呼ばれる広告効果の減衰を制御するパラメータの2つの種類があります。前者のパラメータは[alpha]と[gamma]です。後者は減衰のタイプが幾何型とワイブル型があり、それぞれ幾何型が[theta]を、ワイブル型が[scale][shape]というパラメータを持ちます。
使用するハイパーパラメータを表示し、その可変領域を設定していきます。この例では幾何型(geometric)の減衰を指定したので、設定するのはthetaとalpha/gammaの3つとメディアがTVとNetの2つで計6つ(2*3=6)、さらに学習データ比率を加えて7個です。
#### 2a-2: ハイパーパラメータの定義
# 使用するハイパーパラメータの表示
hyper_names(adstock = InputCollect$adstock, all_media = InputCollect$all_media)
# Adstockと飽和曲線の形状を確認(必要に応じてプロットを表示)
plot_adstock(plot = FALSE)
plot_saturation(plot = FALSE)
# ハイパーパラメータの可変領域を設定
hyperparameters <- list(
Net.Spend_alphas = c(0.5, 3),
Net.Spend_gammas = c(0.3, 1),
Net.Spend_thetas = c(0, 0.3),
Tv.Spend_alphas = c(0.5, 3),
Tv.Spend_gammas = c(0.3, 1),
Tv.Spend_thetas = c(0.1, 0.4),
train_size = 0.7 # ts-cvで使用するトレーニングデータの割合
)
#### 2a-3: ハイパーパラメータをrobyn_inputsに入力
# ハイパーパラメータを含むInputCollectオブジェクトを更新
InputCollect <- robyn_inputs(InputCollect = InputCollect, hyperparameters = hyperparameters)
print(InputCollect)
plot_adstock(plot = TRUE)
plot_saturation(plot = TRUE)とするとハイパーパラメータごとに減衰やサチュレーションの様子を見ることができます。
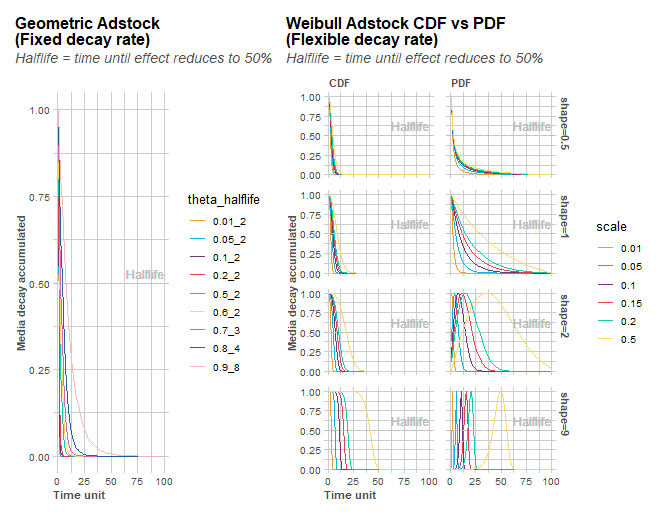
上記はオプションなので、グラフを表示させる必要がない場合は「plot=FALSE」にしてください。
(参考) 各種定義の詳細7https://facebookexperimental.github.io/Robyn/docs/variable-transformations
モデル式
Ridge回帰モデル
Adstockやsaturationの式
- 幾何型Adstockは decay_t,j := x_t,j + θ * decay_t-1,j
- ワイブル型は decay_t,j := 1-(exp(decay_t-1,jj/α))
- saturationは c * (x^α / (x^α + γ^α )) cはメディアxに対して得られた回帰係数
2.5.3 input
#### 2a-3: ハイパーパラメータをrobyn_inputsに入力
# ハイパーパラメータを含むInputCollectオブジェクトを更新
InputCollect <- robyn_inputs(InputCollect = InputCollect, hyperparameters = hyperparameters)
print(InputCollect)2.5.4 モデル構築
モデルを構築していきます。マニュアルでは初期モデルの構築とあるように、この後追加データがある場合それを加えて初期モデルを修正することもできます。
https://facebookexperimental.github.io/Robyn/docs/demo-R-script にある方法とDemoのhttps://github.com/facebookexperimental/Robyn/blob/main/demo/demo.R の方法ではやり方が異なるようで、ここではdemo.Rの方を参考にしています。
################################################################
#### Step 3: 初期モデルの構築
# モデルの全試行とイテレーションを実行
OutputModels <- robyn_run(
InputCollect = InputCollect, # モデル仕様を全て入力
cores = NULL, # 並列計算を行う場合、使用するCPUコア数を指定
iterations = 2000, # 推奨: 2000回(ダミーデータセットに対して)
trials = 5, # 推奨: 5回(ダミーデータセットに対して)
ts_validation = TRUE, # NRMSEを基準にクロスバリデーションを実施
add_penalty_factor = FALSE # 実験的?
)
print(OutputModels)ハイパーパラメータの設定でtrain_size=0.7とすると、ts_validationの訓練、バリデーション、検証に使用されるデータセットの割合は7:1.5:1.5となります。
2000回のiterationsを行う試行を5回ここでは行います。結構時間がかかります。厳密な説明は難しいのですが、ここでのモデリングはリッジ回帰をモデリングしているようで、ハイパーパラメータと通常のパラメータを同時に学習しているようです。この時予測誤差とチャネルのそれぞれの投下費用のシェア率とその係数の比率の距離(要するに現実離れした解にならないように)Prophetに関係する部分のlossと、通常のリッジ回帰の部分のlossに対してMulti-objective optimization8複数の関数を同時に最適化する。理想は複数の関数を同時に最小にする値が存在することだが、普通はそんなものはない。従って、お互いのコストを片方のコストを上げないで下げることができない点を探す。この点をパレート最適点と呼ぶ。https://en.wikipedia.org/wiki/Multi-objective_optimizationを行なっています。Nevergradはこの最適化に対して用いられているようです。
パレート最適解
最後に作成したモデル群の中からパレート最適な物を選ぶ処理?を行うようです。正直ここは少し理解できていません。
# 収束状況をplot
OutputModels$convergence$moo_distrb_plot
OutputModels$convergence$moo_cloud_plot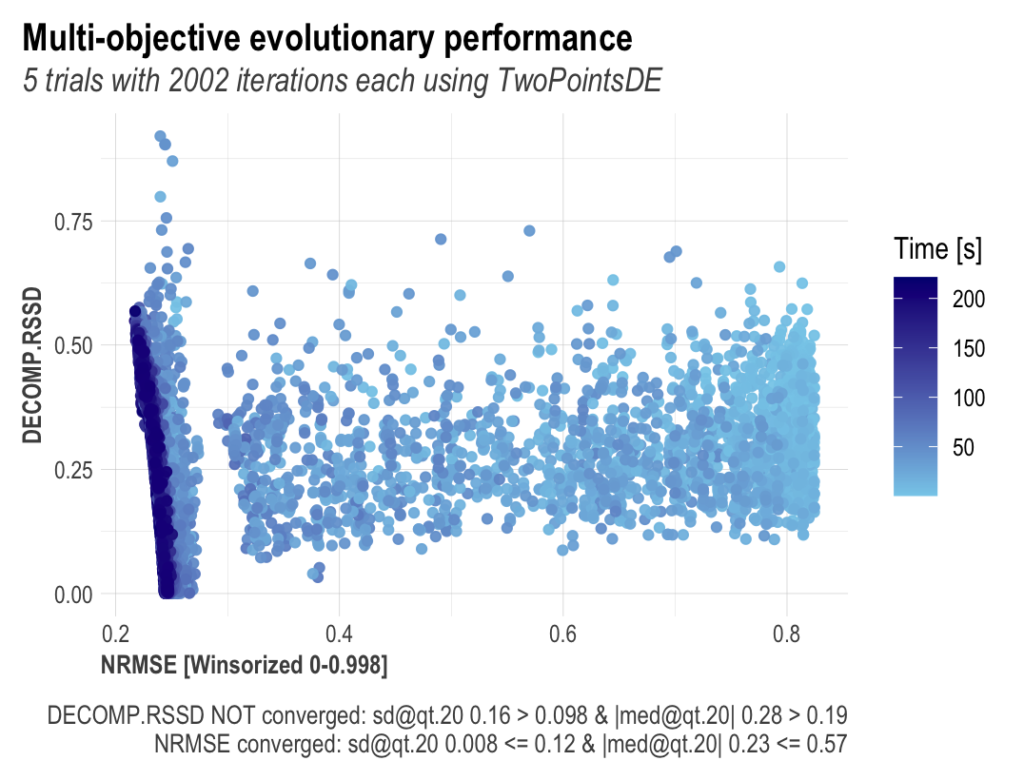
左下の赤い線がパレートフロンティアを表しています。
クロスバリデーションによる誤差の確認
# クロスバリデーションplot
if (OutputModels$ts_validation) OutputModels$ts_validation_plot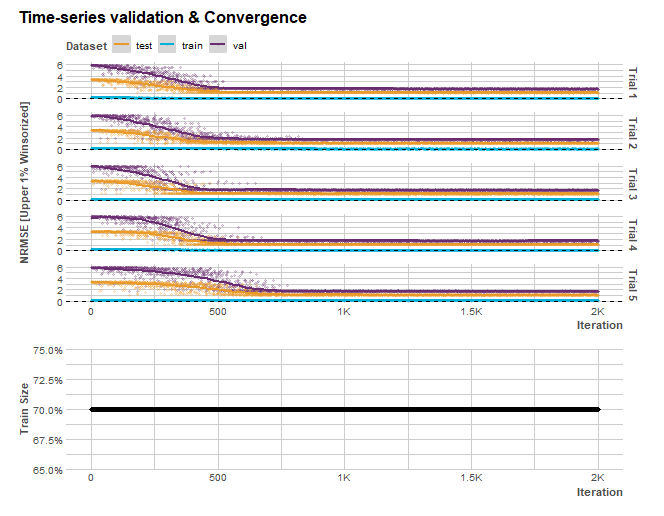
パレート最適化の計算
## パレート最適解の計算, 結果とplotを指定フォルダにexport
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
pareto_fronts = 1, # automatically pick how many pareto-fronts to fill min_candidates (100)
# min_candidates = 100, # top pareto models for clustering. Default to 100
# calibration_constraint = 0.1, # range c(0.01, 0.1) & default at 0.1
csv_out = "pareto", # "pareto", "all", or NULL (for none)
clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters
export = create_files, # this will create files locally
plot_folder = robyn_directory, # 指定したフォルダ内に結果ができる。当該フォルダがない場合cwdにできる
plot_pareto = create_files # Set to FALSE to deactivate plotting and saving model one-pagers
)
print(OutputCollect)pareto_fronts = 1は、NRMSEとDECOMP.RSSDのトレードオフを考慮した最良のモデルを返します。pareto_frontsを増やすことで、より多くのモデルの選択肢を得ることができます。pareto_fronts = “auto”は、少なくとも100の候補を含む最小のフロントを選択します。この閾値をカスタマイズするには、min_candidatesの値を設定します。
また、clusters=TRUEとすると、ROASが似たもの同士を同じクラスタにまとめます。kの値は自動で決定されますが、多くの場合、3になるようです。別にそう言うわけではないようです。出力された「pareto_clusters_wss.png」を見るとクラスタ数が決まる過程がわかります。
実行後、はじめに定義したresultsのフォルダパス傘下に以下のファイルが出力されます。X_YYY_Z.pngの文字列からなるファイルはそのモデルのone-pager repotです。(おそらくですが、先頭のXが何番目のtrialかを表しているようで、残りの2つの数字はiterationsの何番目に相当するかを表しているようです。(内部のコードを読むと(YYY-1)*コア数+Z=itaretionの何番目かとなっている)。
X_YYY_Zファイルの個数はクラスタ数だけあります。おそらくそのクラスタのベストソリューションが表示されるようです。
ne-pager report(ここでは上図の例として1_279_1の)を見てみます。
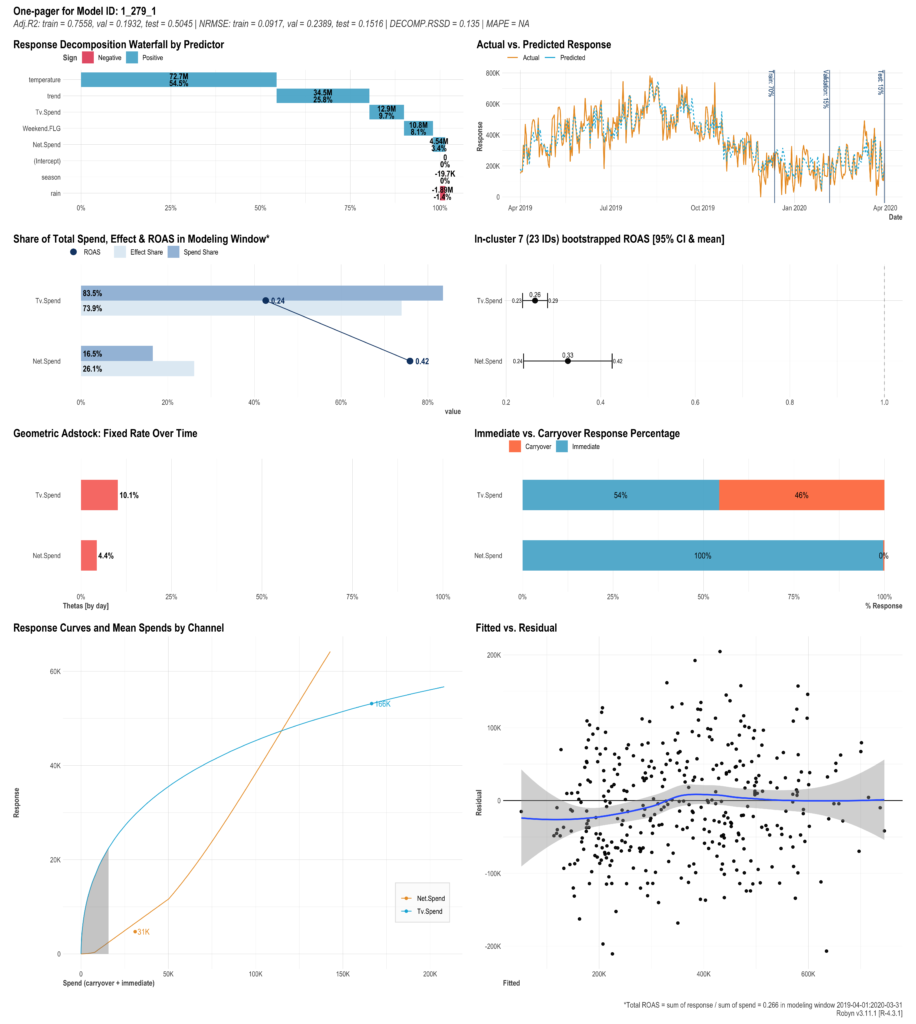
- 左上の図:ウォーターフォール図 成果変数への全体寄与を1とした場合の各要素の寄与割合を示した図です。一番寄与が高いのが「平均気温」、次が「trend」、その次が「週末かどうか」です。ここではTVの寄与はNetより大きいと示されています。メディアの寄与の比較はあくまで投下量ベースであるため、効率は考慮されていません。
- 右上の図:時系列折れ線グラフ 実際の値と予測値のプロット図です。概ね実績値と予測値が近い動きをしていることがわかります。train/valid/testそれぞれの場合が示されています。
- 上から2番目左の図:横棒グラフとROIの折れ線グラフ メディアの実際の投下シェアと、成果変数のシェアのグラフです。赤い折れ線はROIです。全体比の寄与ではTVの方が大きいのですが、ROIではNetの方が大きいことが分かります。成果指標をconversionにすると、ROIの代わりにCPAが出力されるようです。
- 上から2番目右の図:ROIの信頼区間 ブートストラップ法で作成したROIの信頼区間。
- 上から3番目左の図:広告効果の減衰グラフ 広告効果の減衰の程度をそれぞれのメディアごとに示しています。幾何的減衰(geometric)の場合、θの値そのもののようです。
- 上から3番目右の図:効果の即時性とcaryover効果の割合 広告効果の即時性と継続性の比率を横積み上げ100%グラフで表したものです。
- 左下の図:saturationのプロットグラフ saturation効果をそれぞれのメディアで記述しています。Netの方が飽和しにくい、つまり効果の逓減が小さいことが示されています。
- 右下の図:残差プロット 実績と予測値の残差プロットです。一般論として残差に偏りがあれば説明変数だけで説明できていない要因があると考えられます。
本ツールで算出しているROIの定義に関しては調査中ですが一般的な分子から投下量を控除する定義ではなく、成果/投下量で定義しているようです9https://github.com/facebookexperimental/Robyn/blob/main/demo/schema.R?fbclid=IwAR34C6gkz9oeWjX4cPxOUToTIoIvNfopUh0CmZQnqSN5DZX8pRtuSx0joOY。
2.6 モデルの選択
前項のフォルダの中から、ビジネスの実情に合ったモデルを一つ選びます。後の最適化で使用するためにjson形式でモデルをexportします。
################################################################
#### Step 4: モデルの選択と保存
# 選択するモデルのIDを指定(上で実行したモデルから選択)
select_model <- "1_279_1"
# バージョン3.7.1以降: JSON形式でモデルをエクスポート(RDSファイルより高速で軽量)
ExportedModel <- robyn_write(
InputCollect = InputCollect,
OutputCollect = OutputCollect,
select_model = select_model,
export = create_files
)
print(ExportedModel)
# 選択したモデルのOne-Pagerを作成
myOnePager <- robyn_onepagers(
InputCollect = InputCollect,
OutputCollect = OutputCollect,
select_model = select_model,
export = FALSE
)2.7 予算の最適化
様々な条件で最適解を求めることができます。ここでは、元のデータで与えられた予算内で売上を最大化する解を求めます。
################################################################
#### Step 5: 選択したモデルで予算最適化を実施
# 選択したモデルのメディアサマリーを確認
print(ExportedModel)
# 注意: 制約条件の順序は次の順番で指定する必要があります
InputCollect$paid_media_spends
# シナリオ "max_response": 与えられた予算での売上最大化を目指した予算最適化を実施
# 例 1: date_rangeを指定しない場合、直近1カ月の予算最適化を行う
AllocatorCollect1 <- robyn_allocator(
InputCollect = InputCollect,
OutputCollect = OutputCollect,
select_model = select_model,
# date_range = NULL, # 指定しない場合は直近1カ月が対象期間となる
# total_budget = NULL, # 指定しない場合はdate_range内の総支出額がデフォルト
channel_constr_low = c(0.7, 0.7), # メディア数と同じ長さで指定
channel_constr_up = c(1.2, 1.2), # メディア数と同じ長さで指定
# channel_constr_multiplier = 3, # メディア予算制約の拡張係数(必要なら指定)
scenario = "max_response", # シナリオ: 最大レスポンスを目指す
export = create_files # 結果をファイルにエクスポートするかどうか
)
# 最適化の結果を表示&プロット
print(AllocatorCollect1)
plot(AllocatorCollect1)実行するとresultsフォルダ内に、1_279_1_reallocated_best_roas.pngという画像ファイルができます。
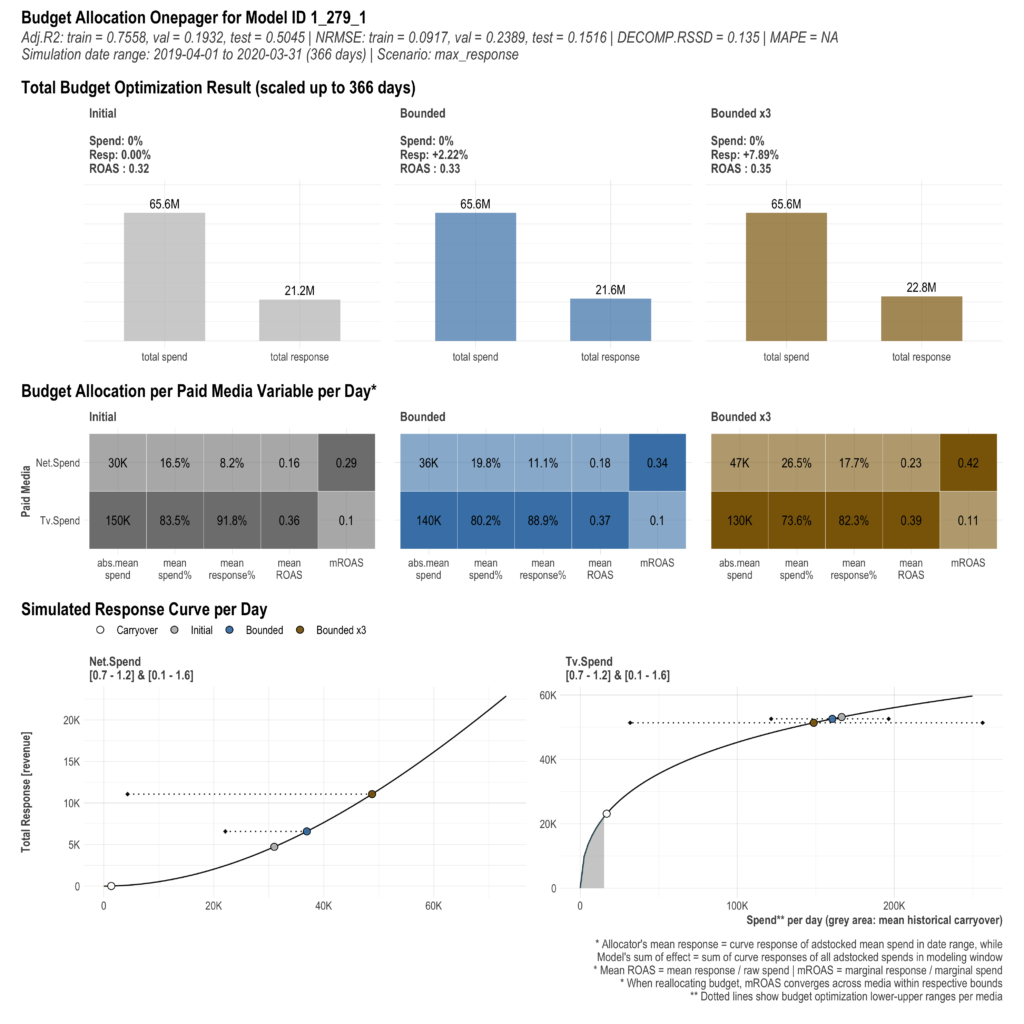
Boundedは、「channel_constr_low/high」で指定した上下限の範囲内での最適解を示します。一方、Boundedx3は、その上下限の3倍まで許容した場合の最適解を示します(おそらくですが、間違っていたらすいません)。 「channel_constr_low/high」を指定する理由は、直近の予算と大きく乖離する解は実務上使いにくいという実情に対応するためです。
他にも色々な条件下での最適化方法がありますが、そちらはこちらを参照ください。
まとめ
meta社のRobynを用いたAutomated MMMの実践を行いました。入力データとハイパーパラメータを与えることで売上とメディアの関係をモデリングすることができます。そして得られたモデルを用いて最適化予算のアロケーションを行うことが可能です。
更にここでご紹介した方法以外にも、追加データでモデルを構築するrefreshやおよモデルのcaribrationなどの機能があります。ここでご紹介できなかったものに関しては、今後どこかで解説記事を書きたいと思います。
一方でAutoと言いつつもかなり、細かいパラメータの設定を作業者が行う必要性があります。
Robynを始めとしたMMMに関してのご相談は是非弊社までお願いいたします。
当ツールは今でも改良が行われているようなので、最新版に関しての情報は公式HPをご確認ください。
無料相談大歓迎です。ご興味ございましたら、お問い合わせはこちらから宜しくお願い致します。