前回、前々回と回帰モデルについて説明してきました。これらは教師あり学習でしたが、今回説明するクラスタリングは教師なし学習に分類されます。マーケティングの現場では回帰モデルと並んで使用される手法です。
クラスタリング概要
分類
クラスタリングは与えられたデータ間の距離を元に類似したもの同士を同じグループ(クラスタ)に分ける手法です。データ間の距離を使用するため教師ラベルが不要、つまり教師なし学習に分類されます。元のデータは数的変数であることが望ましいですが、カテゴリ変数を持つデータに対しても適用できる手法があります。
マーケティングにおけるクラスタリング活用例
顧客をあるグループに分ける、商品をあるグループに分けるなどの活用例が挙げられる。

有用性と弱点
有用性
- 説明しやすさ。顧客ペルソナなどを分かりやすい言葉や表にして説明できる。
- 解釈に数理的な困難がないため、分析者の技量によるところが少なく誰でも利用できる。
- 多様なプラットフォームで実行可能。R/Python/SAS/SPSSいずれでも実行できる。
- 教師データが不要である。
弱点
- 予測値を出してくれるわけではないため、予測モデルとして使用できない。
- 分布が極端な変数(例えばほぼ0の値しかとらない変数)が多いと一部のクラスタ間の件数分布に偏りができる。
- クラスタを用いて何をするかの要件を明確に詰めていないと、それを活かすことができない。
一般論
手法一覧
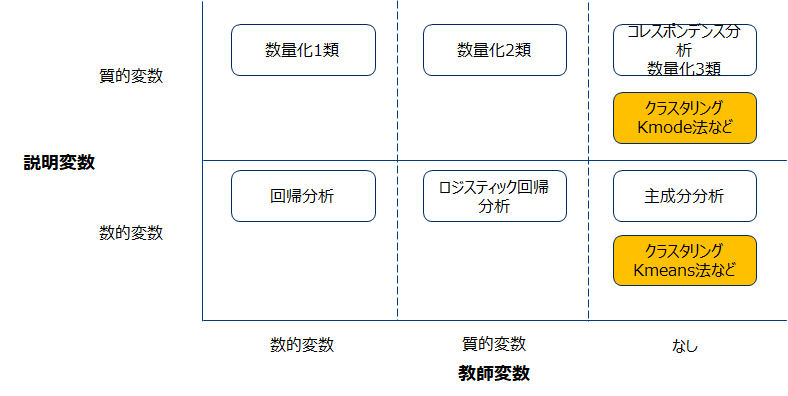
データの型や、階層の有無により以下の代表的な手法に分けられます。
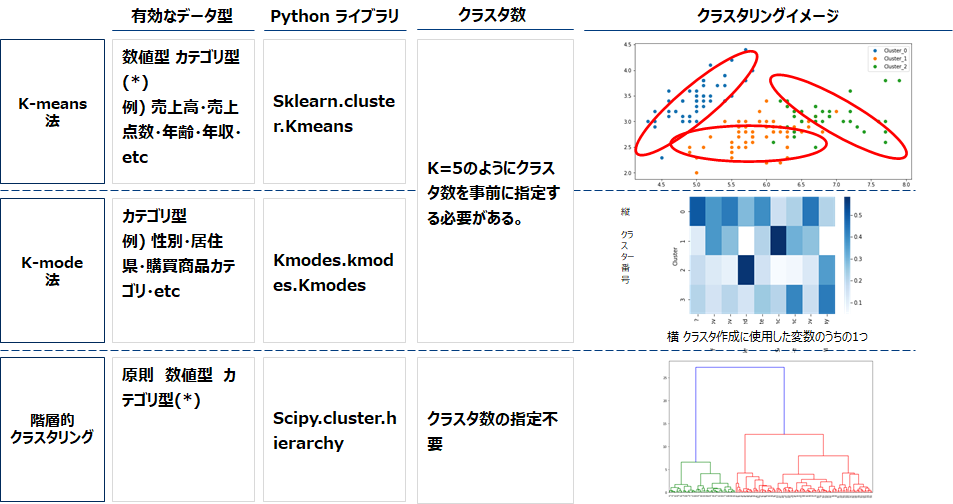
* カテゴリ型をダミー変数に変換すれば実行可能です。一方で0/1の分布(2項分布)となるので、k-means法ではクラスタ件数分布が偏りやすい。
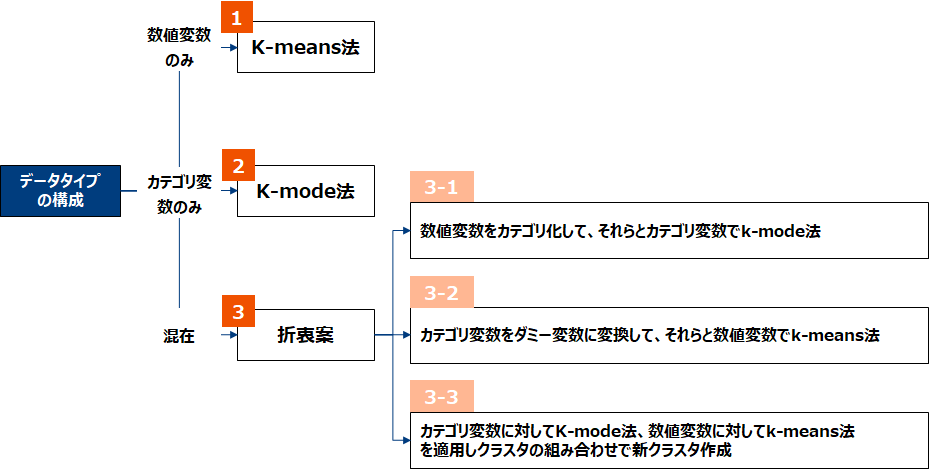
手法選択フロー
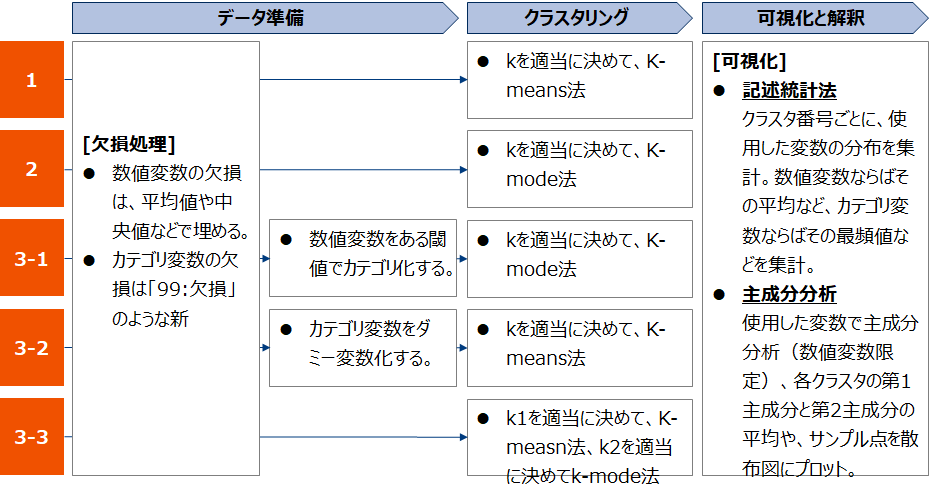
実務的には前頁図表の上2つ、「k-measn法」「k-mode法」を用いる事が多いため、本稿でもこの2つに絞って話を進めます。
分析手順
使用する手法が決まったら、以下の手順でクラスタリングを実行していきます。回帰モデルと比較すると、工程数が少なく、また統計的検定が不要であるため理解しやすいと思います。
実習1 k-means法クラスタリング
実習用のpgmは以下のリンクからDLしてください。
https://github.com/mitsu666/Lecture2021/blob/main/Lecture08_Clustering.ipynb
データ準備
実験対象データは(毎度おなじみの)sklearnに付属しているbostonというボストンの住宅価格のデータセットを使用します。各カラム名は以下の通りです。カラム名は@markit様の記事から引用しています。
CRIM: 町別の「犯罪率」
ZN: 25,000平方フィートを超える区画に分類される住宅地の割合=「広い家の割合」
INDUS: 町別の「非小売業の割合」
CHAS: チャールズ川のダミー変数(区画が川に接している場合は1、そうでない場合は0)=「川の隣か」
NOX: 「NOx濃度(0.1ppm単位)」=一酸化窒素濃度(parts per 10 million単位)。この項目を目的変数とする場合もある
RM: 1戸当たりの「平均部屋数」
AGE: 1940年より前に建てられた持ち家の割合=「古い家の割合」
DIS: 5つあるボストン雇用センターまでの加重距離=「主要施設への距離」
RAD: 「主要高速道路へのアクセス性」の指数
TAX: 10,000ドル当たりの「固定資産税率」
PTRATIO: 町別の「生徒と先生の比率」
B: 「1000(Bk – 0.63)」の二乗値。Bk=「町ごとの黒人の割合」を指す
LSTAT: 「低所得者人口の割合」
MEDV:「住宅価格」(1000ドル単位)の中央値。通常はこの数値が目的変数として使われる
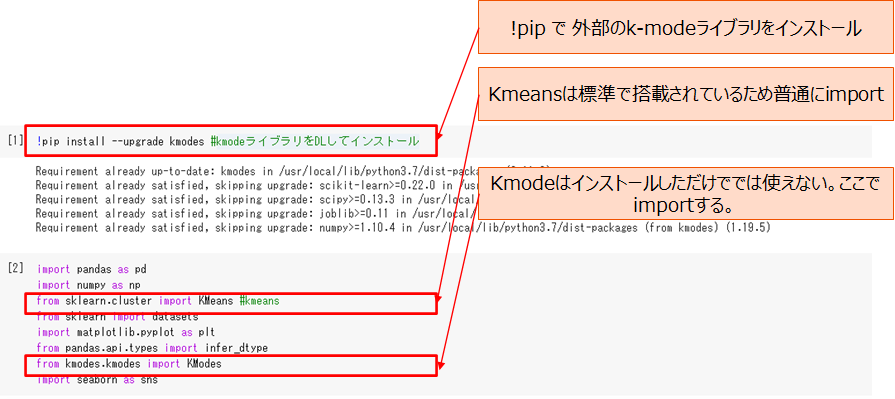
(参考 必要なライブラリを読み込む)
kmodes法はあとで使用しますが、google coloboratory標準でインストールされていないため、あらかじめインストールしておきます。
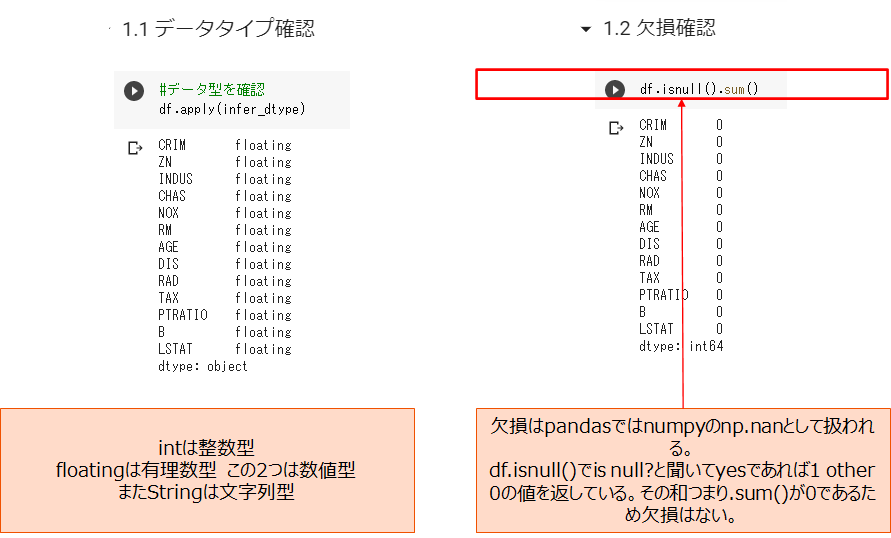
データ確認
全てfloating(浮動小数点)型、つまり数値型です。また欠損はありません。
クラスタリング
わずか数行のコードを実行するだけで、クラスターを作成できます。
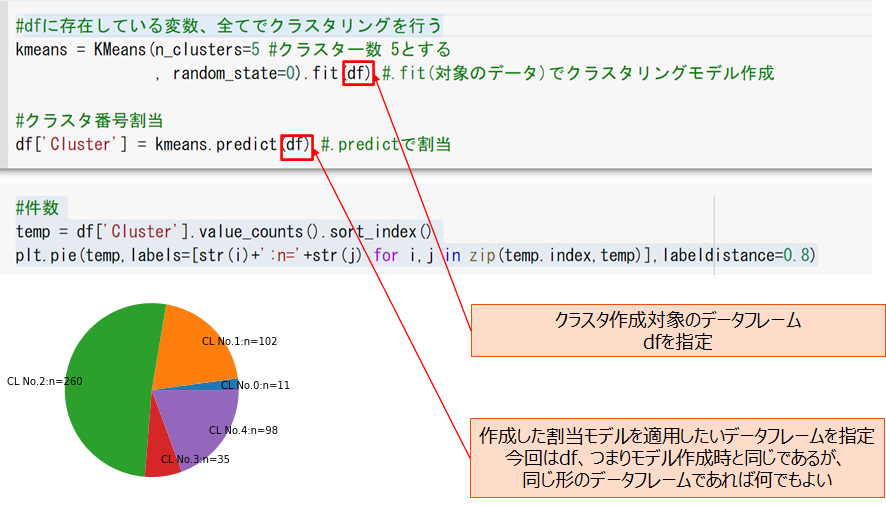
11件のクラスタができてしまったため、k=5からk=4にして再度やり直します。
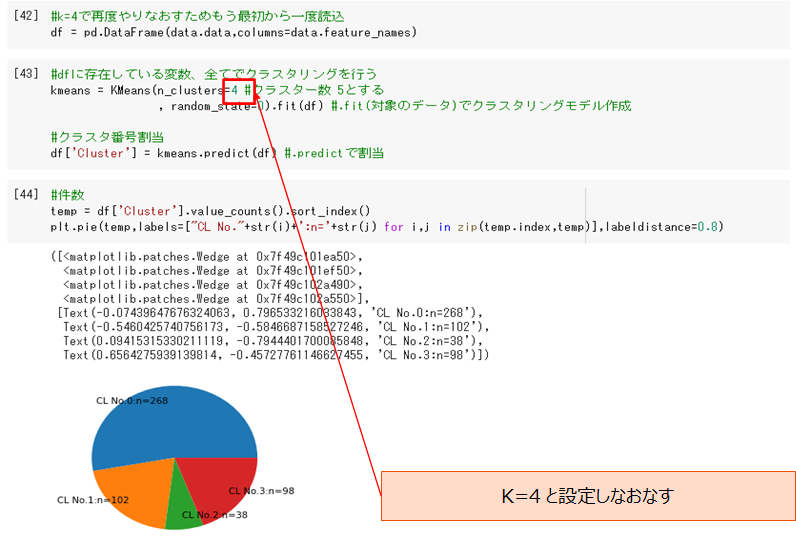
クラスターの特徴を解釈する 記述統計法
4つのクラスターはどのような特徴を持つでしょうか。これらを理解することはマーケティングにおいて重要です。時間をかけるべきはクラスタリングモデルの作成ではなく、この特徴を見出す作業であるといっても過言ではありません。記述統計法は記述統計量(頻度分布や、平均値)を元に人が目で判断しクラスタを特徴づける方法です。
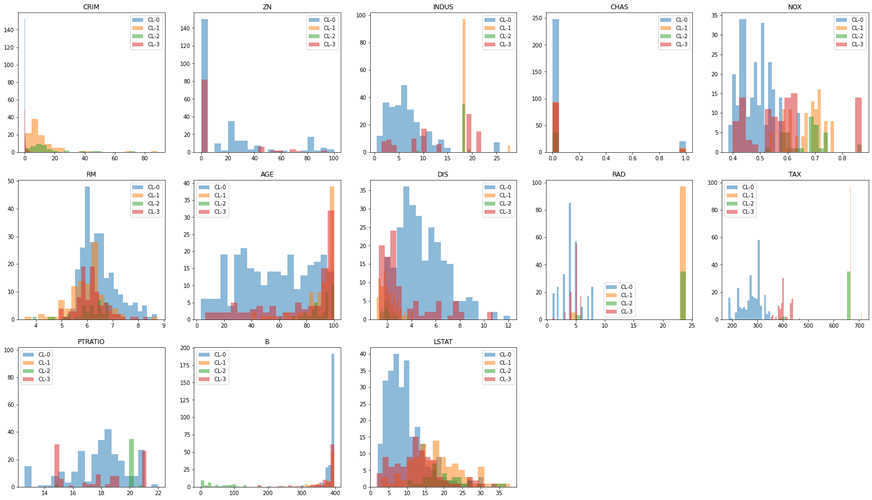
明らかにクラスタごとに変数の分布が異なることが分かります。
各クラスタ、変数ごとの平均値を算出します。ヒートマップを作成すると分かりやすいと思います。
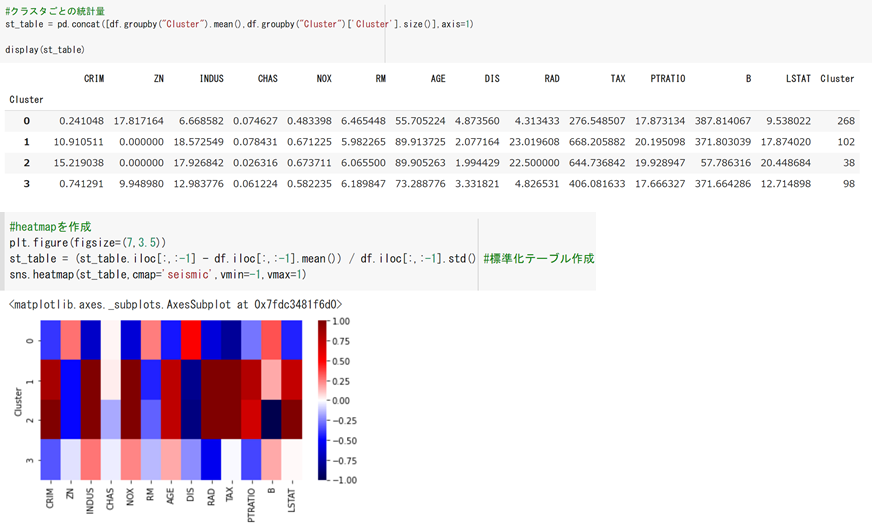
まとめると以下のような感じでしょうか。

実習2 k-modes法クラスタリング
データ準備
実験対象データは、UCI Machine Learning Repositoryより取得したCensus Income データセット「Adult Data Set」を使用します。このデータセットには以下の変数が含まれています。引用元はこちらです。
age:年齢
workclass:雇用形態
fnlwgt:回答者への重み(メタデータ)
education:学歴
education-num:教育年数
marital-status:未婚・既婚ステータス
occupation:職業
relationship:続柄
race:人種
sex:性別
capital-gain:資本獲得
capital-loss:資本金の減少
hours-per-week:週あたりの労働時間
native-country:生まれた国
データ確認
一部整数型(integer)、その他は文字列型(string)です。今回はk-mode法の実習ですので、string型変数のみを抽出します。
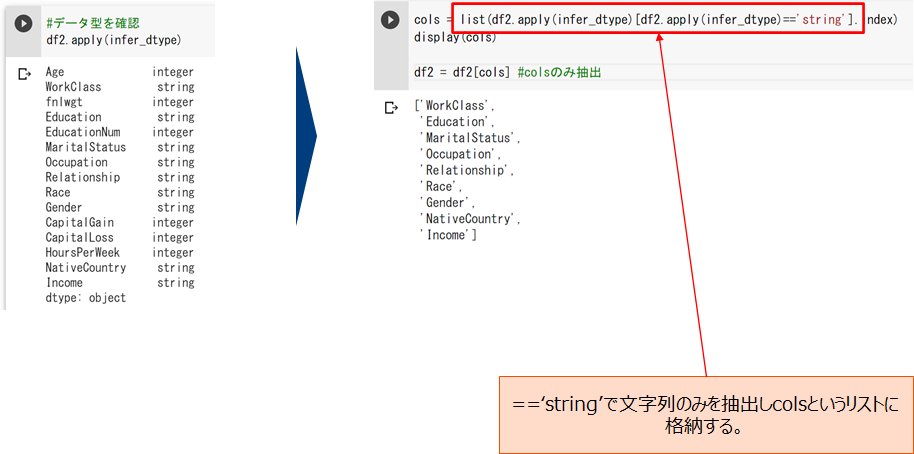
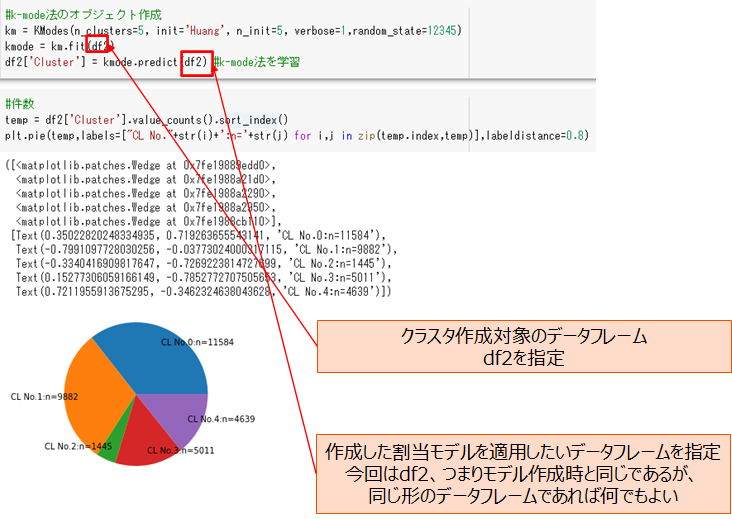
クラスタリング
K-means法とほぼ同じやり方でクラスタリングを実行します。
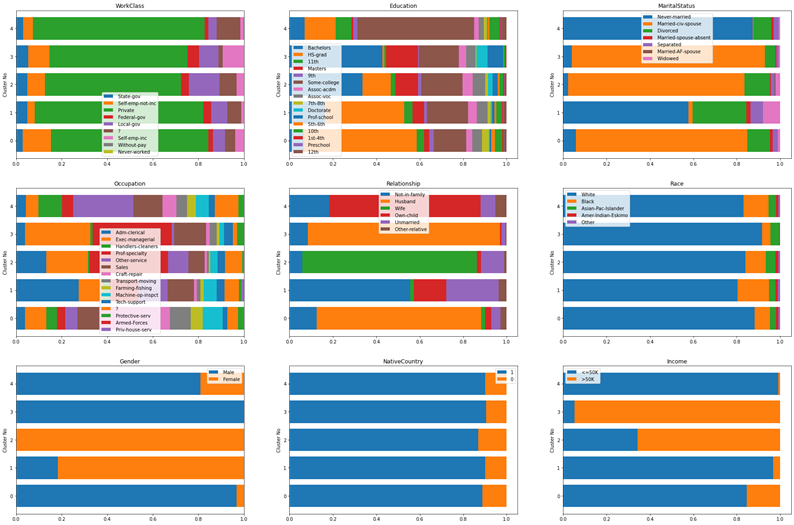
特徴を可視化する
数値変数ではなくカテゴリ変数を対象としているため、積上げ構成比を用いました。
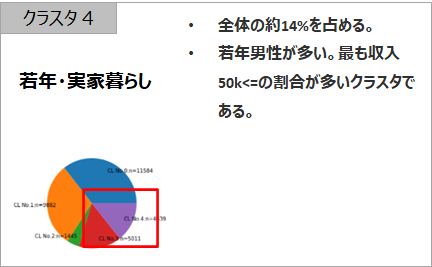
クラスターの特徴を解釈する 記述統計法
同じようにまとめてみました。

以上です。大変便利な手法なので、ぜひマーケティング実務で使って頂ければと思います。