一般的に需要予測はサプライチェーンマネジメントの文脈で語られることが多いです。しかし広告投下量は需要をコントロールする変数と考えられますので、マーケターの方でも需要予測を知っておいて損はないはずです。本稿では需要予測の概要を説明し、次に需要予測で用いるツールfacebookのProphetを紹介します。そして実際にSIGNATEのコンペで使用された引越し需要予測データを用いて需要予測を行います。
需要予測について
重要性
需給のバランスが不均衡であると様々な問題が生じます。例えば供給不足であれば品切れを起こしたり、供給過多であれば過剰な在庫や人員をかかえるなどのロスが発生します。そのため精度高く需要予測を行いそれに基づいた販売・生産計画を立案することが重要になります。
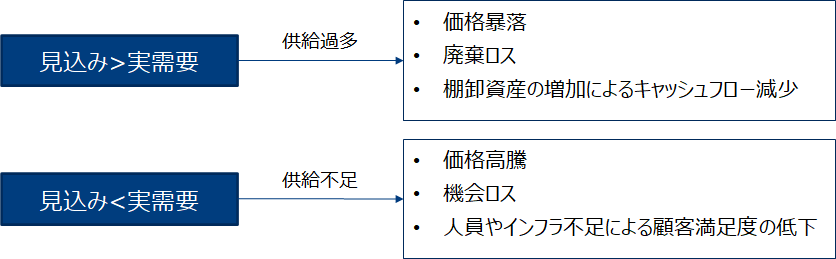
(参考) その他の具体例

(*1) https://www.enecho.meti.go.jp/about/special/johoteikyo/balance_game.html
(*2) https://www.hepco.co.jp/network/renewable_energy/efforts/problem/keep_quality.html
(*3) https://japantaxi.co.jp/news/pr/2018/03/09/0054/
(*4) https://www.sevenbank.co.jp/oos/adv/tmp_192_04.html
解決手段の1つ
需要予測は見込み販売・生産において需給バランスを均衡させるための手段です。受注してから仕入・生産をする、予約注文のみで販売することで需給バランスの調整を行う場合もあります。何が最適な選択肢かは業種・業態や対象企業の戦略によります。

* 製造業では「受注生産」は「見込み生産」の反対の概念で使用されることが多い。
手法
従業員の勘と経験による予測は古くから行われています。最近では統計モデルやヒストリカルデータを学習させた機械学習・AIの利用も進んでいるようです。

John C. Chambers, Satinder K. Mullick, and Donald D. Smith 「How to Choose the Right Forecasting Technique」 HBR と https://www.brillio.com/insights/choosing-the-right-forecasting-technique/を参考に作成
機械学習・AIモデルの強み弱みと向き不向き
機械学習・AIモデルは需要予測の自動化や予測精度向上に資する一方で学習データが必要であることから新製品の販売予測のようなものには適しません。

予測地点と予測期間の整理
いつの時点からいつまで先の時点の需要を予測するのかを決める必要があります。通常小売りなどの発注を行う業態では、発注日時点から発注リードタイム先(*5)の需要を予測します。
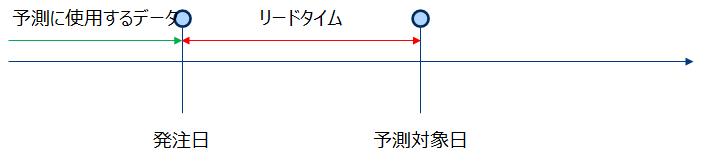
正確には定期発注方式と定量発注方式で発注日は固定か可変かが違いますが、本稿ではそこには立ち入りません。とにかくいつ時点でどの時点先までの予測するかを決めておこないと需要予測は行えないということを理解しましょう。
(*5) 発注から納品までの期間 この期間を小さくする努力もまたサプライチェーンマネジメントにはかかせない。
予測対象の整理
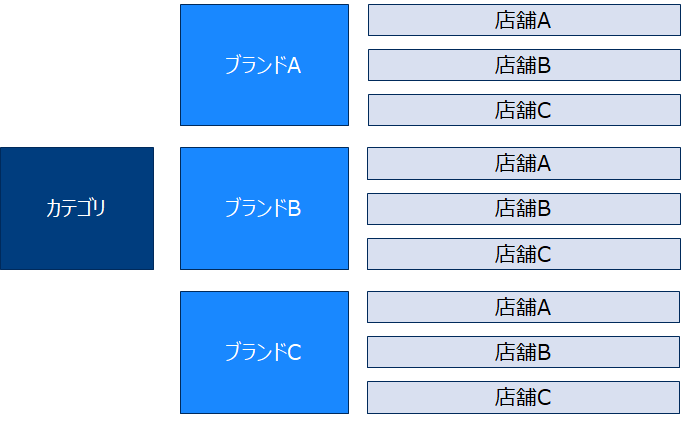
予測単位を決めます。例えば製品カテゴリという単位で予測するのか、製品カテゴリのブランド単位で予測するのかを決定します。
Prophet
ProphetはFacebook社の開発した時系列モデル構築用のOSSです。PythonとRから利用できる。特に需要予測のみに対応しているわけではなく、汎用的な時系列予測ツールです。

HP https://facebook.github.io/prophet/ より
Pythonから使用する
Pythonから使用するには通常の他のライブラリと同様に、インストールするだけです。Jupyter notebookもしくはgoogle colaboratoryのセルに以下のコマンドを打ち込みます。
!pip install pystan==2.19.1.1 !pip install prophet
機能概要
基本機能だけでも簡単に時系列モデルを作ることが可能。さらにオプション機能を用いればさらに詳細な情報を組み込んだモデルを構築できます。

チュートリアル
入力データ
入力データは少なくとも日付(dsという名前にする)と予測したい量(yという名前にする)が必要です。
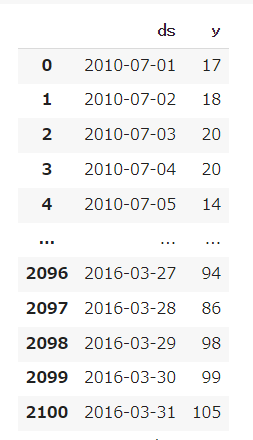
SIGNATE アップル引越しセンター 引越し需要予測コンペより
https://signate.jp/competitions/269/data
基本機能だけで簡単予測
基本機能だけを使用するならば、わずか数行のコードで以下のような出力を得られます。
m = Prophet()
m.fit(df_train_) #df_train_は前項のデータセット
future = m.make_future_dataframe(periods=365) #365日先を予測
forecast = m.predict(future)
fig1 = m.plot(forecast)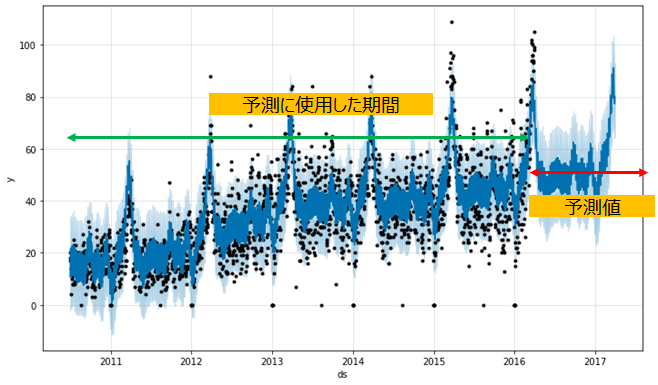
インサイト
予測モデルはトレンド+年次季節性+週次季節性の合成で得られる(基本機能だけを使用した場合)。この3つの成分を可視化することができます。
fig2 = m.plot_components(forecast)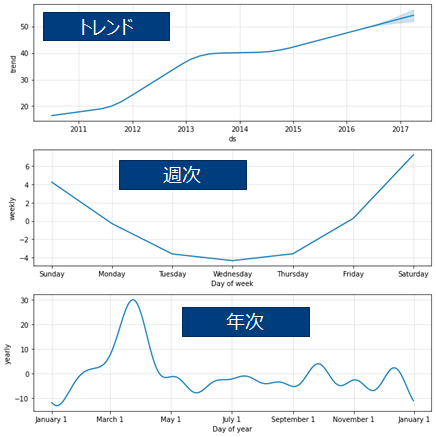
実習
対象課題
SIGNATE(*6)のコンペ課題の一つである「アップル引越し需要予測」を例に取り上げます。2010年07月01日~2016年03月31日までのデータを学習データとして、2016年04月01日から365日分の引越しの実需要を予測します。

(*6) オプトグループ SIGNATE社運営の分析コンペプラットフォーム https://signate.jp/competitions/269/data
対象データ
以下にSIGNATE HP(*7)よりデータの詳細を引用したものを記載しました。

(*7) https://signate.jp/competitions/269/data
処理① 読込まで
Prophetインストール
#prophetインストール
!pip install pystan==2.19.1.1
!pip install prophetimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
from prophet import Prophet
from prophet.plot import plot_forecast_component
from prophet.diagnostics import cross_validation
os.chdir('/content/drive/MyDrive/003_Project/999_other/研修用資料/prophet')データ読込
#read table
df_train = pd.read_csv('train.csv',parse_dates=[0])
df_test = pd.read_csv('test.csv',parse_dates=[0])データ表示
display(df_train)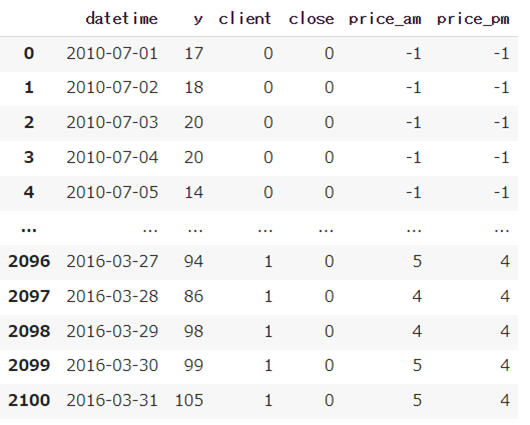
処理② 基礎分布確認
時系列確認
import matplotlib.dates as mdates
fig, ax = plt.subplots(figsize=(14, 4))
ax.plot(df_train['datetime'],df_train['y'])
ax.xaxis.set_major_locator(mdates.DayLocator(bymonthday=None, interval=365, tz=None))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
時系列 clientごと
#変数clientごと
fig, ax = plt.subplots(figsize=(14, 4))
ax.plot(df_train[df_train['client']==1]['datetime'],df_train[df_train['client']==1]['y'],label='client',alpha=0.5)
ax.plot(df_train[df_train['client']==0]['datetime'],df_train[df_train['client']==0]['y'],label='others',alpha=0.5)
plt.legend()
ax.xaxis.set_major_locator(mdates.DayLocator(bymonthday=None, interval=365, tz=None))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.title('client')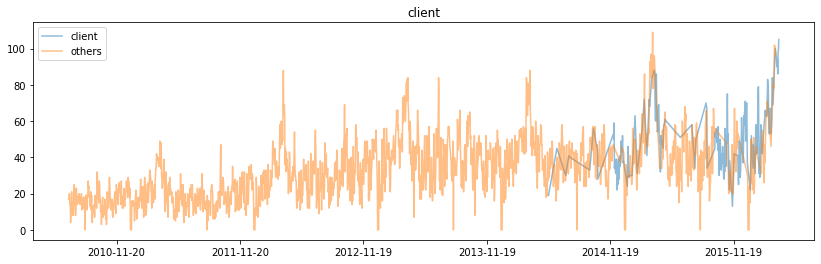
時系列 closeごと
#変数closeごと
fig, ax = plt.subplots(figsize=(14, 4))
ax.plot(df_train[df_train['close']==1]['datetime'],df_train[df_train['close']==1]['y'],label='client',alpha=0.5)
ax.plot(df_train[df_train['close']==0]['datetime'],df_train[df_train['close']==0]['y'],label='others',alpha=0.5)
plt.legend()
ax.xaxis.set_major_locator(mdates.DayLocator(bymonthday=None, interval=365, tz=None))
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
plt.title('close')
pricce 分布
#am_price / pm_price
plt.figure(figsize=(14,4))
l1 = []
for i in sorted(df_train['price_am'].unique()):
l1.append(df_train[df_train['price_am']==i]['y'])
l2 = []
for i in sorted(df_train['price_pm'].unique()):
l2.append(df_train[df_train['price_pm']==i]['y'])
plt.subplot(1,2,1)
plt.boxplot(l1,labels=sorted(df_train['price_am'].unique()))
plt.title('am_price')
plt.subplot(1,2,2)
plt.boxplot(l2,labels=sorted(df_train['price_pm'].unique()))
plt.title('pm_price')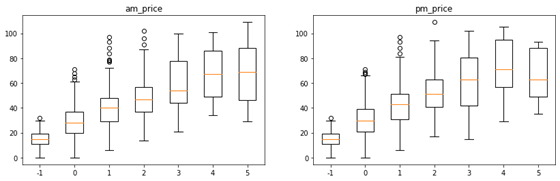
Prophet用にデータ改変
#prophet用に変数名を変更し、一旦余計な変数を落とす
df_train_ = df_train.rename(columns={'datetime':'ds'})[['ds','y']]
display(df_train_)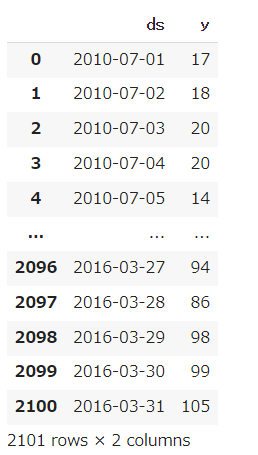
処理③ モデリング シンプルモデル
チュートリアルで取り上げた一番シンプルなモデルを作成し、MAE(つまり予測-正解の差の絶対値の平均)で評価します。
モデルフィット
#モデルフィット
m = Prophet()
m.fit(df_train_)モデル予測(365日先)
#モデル予測
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
fig1 = m.plot(forecast)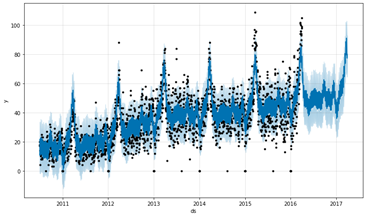
Cutoff以降を評価データ、それ以前730日を学習データとしてそれぞれのcutoffで学習し評価しました。
#モデルをMAEで検証
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
np.abs(df_cv['y'] - df_cv['yhat']).groupby(df_cv['cutoff']).mean().sort_index()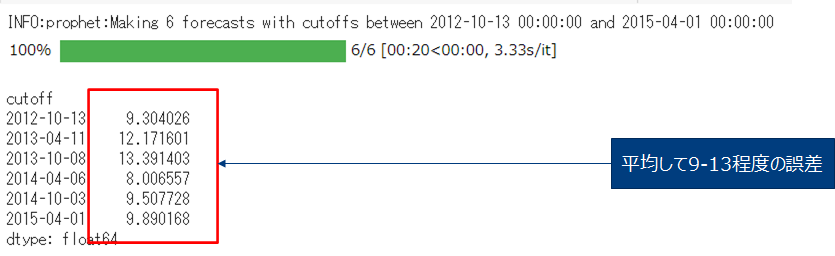
処理③ モデリング 祝日追加モデル
祝日は当然、土日と同様に引越し需要が伸びるはずです。Prophetには祝日の情報を扱えるオプションがあります。
祝日
#日本の祝日
m = Prophet()
m.add_country_holidays(country_name=‘JP‘)#日本の祝日
m.fit(df_train_)
m.train_holiday_names
* 天皇誕生日は平成時代の12/23になっていることに注意
予測
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
fig1 = m.plot(forecast)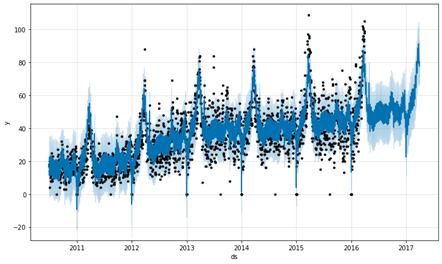
評価
#モデルをMAEで検証
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
np.abs(df_cv['y'] - df_cv['yhat']).groupby(df_cv['cutoff']).mean().sort_index()
処理③ モデリング 月次季節性+他の変数投入モデル
シンプルモデル+祝日+月次季節性+他の変数(close client price)を追加します。
モデル定義
m = Prophet()
m.add_country_holidays(country_name='JP') #祝日追加
m.add_seasonality(name='monthly', period=30.5, fourier_order=5) #月次季節性(30.5日)追加
m.add_regressor('client') #元データにあるclient追加
m.add_regressor('close') #元データにあるclose追加
m.add_regressor('price_am') #元データにあるprice_am追加
m.add_regressor('price_pm') #元データにあるprice_pm追加
#各種変数を学習データdf_train_に追加
df_train_['client'] = df_train['client']
df_train_['close'] = df_train['close']
df_train_['price_am'] = df_train['price_am']
df_train_['price_pm'] = df_train['price_pm']
m.fit(df_train_)予測する
future = m.make_future_dataframe(periods=365)
#各種変数を予測データfutureに追加
future['client'] = pd.concat([df_train['client'],df_test['client']]).reset_index(drop=True)
future['close'] = pd.concat([df_train['close'],df_test['close']]).reset_index(drop=True)
future['price_am'] = pd.concat([df_train['price_am'],df_test['price_am']]).reset_index(drop=True)
future['price_pm'] = pd.concat([df_train['price_pm'],df_test['price_pm']]).reset_index(drop=True)
forecast = m.predict(future)
fig1 = m.plot(forecast)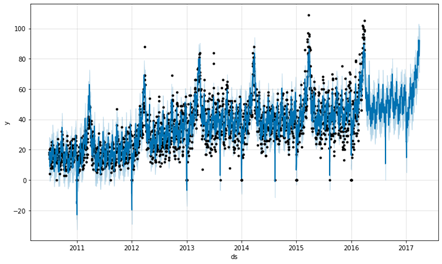
構成要素を分解
fig = m.plot_components(forecast)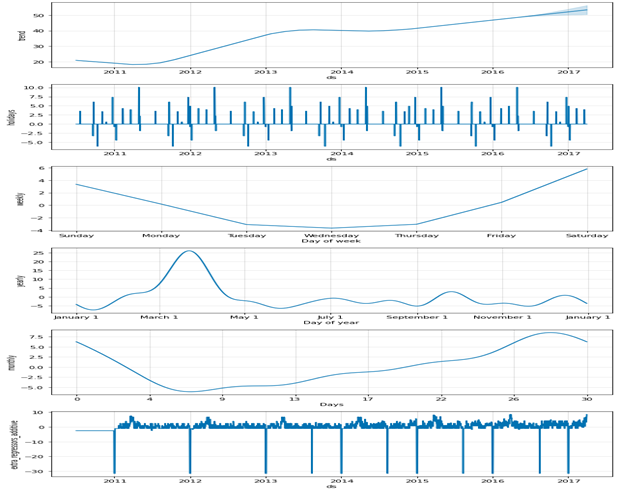
評価
#モデルをMAEで検証
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
np.abs(df_cv['y'] - df_cv['yhat']).groupby(df_cv['cutoff']).mean().sort_index()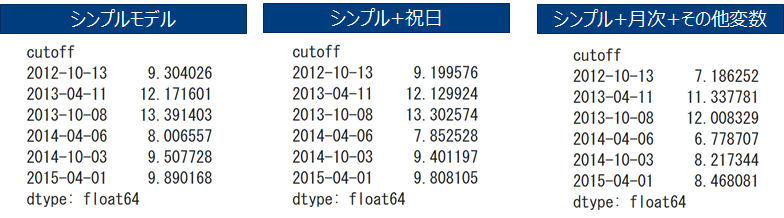
処理④ 手元で一番評価の高いモデルをコンペに投稿する
SIGNATEコンペ投稿ページより、出力したCSVを投稿してみる。全参加者の上位60%の順位となりました(2021年7月)。
少し工夫する (1) 乗法季節モデル
2013年以前以後で少しトレンドとそのバラツキが異なるため、それを考慮してモデルを作成します。
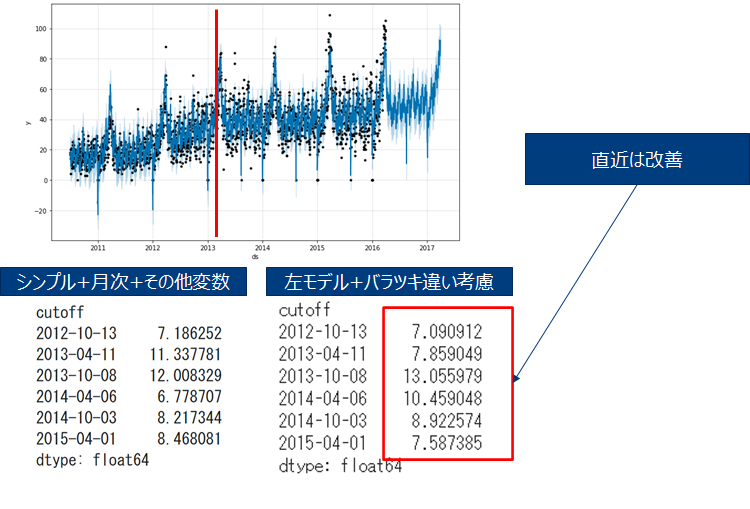
一気に132/476位まで順位が上がりました。
おわりに
まずProphetが簡易かつ強力な手法であることが、理解いただけたでしょうか?facebookが今後開発を続けるのかどうかという疑問は残りますが、とにかく現状では需要予測に対して強力なツールです。
手法的には一般化加法モデルという手法を使っており技術的に興味ある方は、元論文https://peerj.com/preprints/3190/をご覧ください。