
[想定している読者像]
イベント興行や、旅行など季節サービスを提供されている会社の経営企画などのご担当者様、企業のデータサイエンティストやデータアナリストの方。ダイナミックプライシングをpythonで実装したい人。
[コンテンツ属性]
ビジネス:★☆☆☆☆
データアナリティクス:★★★★★
エンジニアリング:★☆☆☆☆
前回ダイナミックプライシングの一般論と事例をご紹介しました。本稿ではpythonを用いたデータドリブン・ダイナミックプライシングについて解説します。
1. 仕組みと実践
1.1 ダイナミックプライシングに用いられるアルゴリズム
価格を需要・供給に応じてフレキシブルに変更すること、およびその仕組みの総称をダイナミックプライシングと呼びます。始まりは担当者の「感・経験・度胸」で価格を決めるアナログな考え方でした。しかし近年はデータを活用したアルゴリズムによる価格決めが主流です。主に以下のようなものがあります。(参考 1 https://induraj2020.medium.com/implementing-dynamic-pricing-strategy-in-python-part-1-5bd7e1a1f382)
- ルールベースプライシング
- 時系列予測
- 機械学習
- 強化学習
- バンディットアルゴリズム (強化学習の1種)
今回ご紹介するのは、データを活用した機械学習のアルゴリズムです。
1.2 実践に使用するデータ
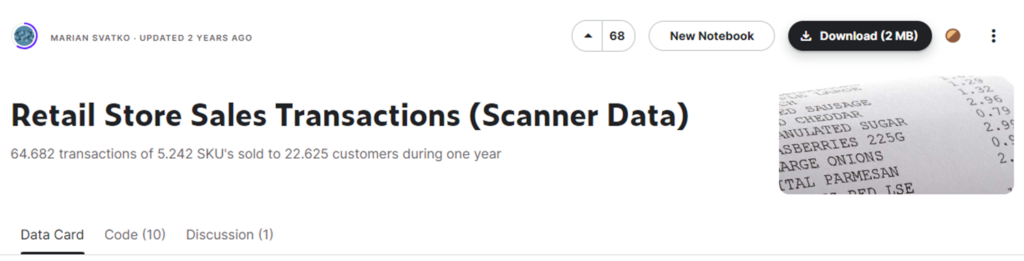
kaggle HPからDL可能な「Retail Store Sales Transactions (Scanner Data)」を使用します2https://www.kaggle.com/datasets/marian447/retail-store-sales-transactions。
- 小売店の電子POSで個々の製品のバーコードを「スキャン」して得られたデータ。
- 匿名化されたデータセットには、1年間に22,625人の顧客に対して販売された5,242のSKUの64,682件の取引データが含まれている。
以降の作業はhttps://blog.devgenius.io/how-to-build-a-dynamic-pricing-system-using-machine-learning-in-python-ad6d4e4292f8を参照しました。
1.3 実践
1.3.1 データDL
データをダウンロードし読み込みます。なお本節以降、jupyter notebook上で作業を行います。Kaggle HP (https://www.kaggle.com/datasets/marian447/retail-store-sales-transactions) よりダウンロード任意のフォルダに展開します。
1.3.2 データ読み込み
必要なライブラリをimportし、pandasでデータを読み込みます。
ライブラリ
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
import os
import seaborn as snsread csv
# csvファイルの読み込み
data = pd.read_csv('scanner_data.csv')
# 表示
display (data.head())1.3.3 データ前処理
価格などの要素から需要を予測するモデル(F(p))を作成するために、必要な前処理を行います。
前処理
def add_discount_data(df):
'''
夏と冬の月における特定の日に、疑似的なディスカウントを行う。
'''
discounts = []
for date in df.Date:
# '夏冬ディスカウント
if date.month in [5, 6, 7, 11, 12]:
discounts.append(np.random.random() * 0.5)
else:
discounts.append(0.0)
return discounts
# データクリーニング
# Set date column as datetime object
data.Date = pd.to_datetime(data.Date)
# 疑似的なディスカウント率を追加
data['discount%'] = add_discount_data(data)
# item単価を追加
data['item_price'] = data.Sales_Amount / data.Quantity
# 不要カラムを削除
data = data.drop('Unnamed: 0', axis=1)# 下記の変数は、最適化したい対象を設定します。製品カテゴリーまたは製品自体です。
# カテゴリーの方が製品よりも少ないため、計算上はカテゴリーの方が簡単、しかし各製品に対しても可能。
product_grain = 'SKU_Category'
# 定めた粒度でdateでagg
# - Total Quantity sold
# - Total Sales Amount
# - Average Discount in percentage
# - Average item price
sales_by_date_and_category = data.groupby(['Date', product_grain]).agg(
{
'Quantity': 'sum',
'Sales_Amount': 'sum',
'discount%': np.average,
'item_price': np.average
}
).reset_index()
# 日と月を別のカラムに入れる
sales_by_date_and_category['day'] = sales_by_date_and_category.Date.dt.day
sales_by_date_and_category['month'] = sales_by_date_and_category.Date.dt.month
# 商品カテゴリーをラベルエンコーディングする
encoder = LabelEncoder().fit(sales_by_date_and_category[product_grain].values)
sales_by_date_and_category[product_grain] = encoder.transform(sales_by_date_and_category[product_grain])
sales_by_date_and_category作成したテーブル
1.3.4 モデリング
# 販売数量を予測するモデルを作成:
# - product
# - discount
# - price
# - day
# - month
# ランダムフォレスト回帰木を用いる
rf = RandomForestRegressor()
X = sales_by_date_and_category[[product_grain, 'discount%', 'item_price', 'day', 'month']]
y = sales_by_date_and_category['Quantity']
rf = rf.fit(X, y)1.3.5 予測値付与・評価
評価は平均絶対誤差、本手順では訓練・検証の分割を行っていないため汎化性能の評価になっていないことに注意してください。(今回の問題の本質ではないので、省略した)
# 予測数量を付与する
sales_by_date_and_category['predicted_quantity'] = rf.predict(X)
# 絶対平均誤差を計算
sales_by_date_and_category['error'] = abs(sales_by_date_and_category.Quantity - sales_by_date_and_category.predicted_quantity)
print(f"Mean Absolute Error: {sales_by_date_and_category['error'].mean()}")1.3.6 需要曲線の可視化
# カテゴリID 69番
# 4月の需要曲線
category_num = 69
tmp = sales_by_date_and_category[(sales_by_date_and_category[product_grain]==category_num) & (sales_by_date_and_category["month"]==4)]
sns.regplot(x=tmp['predicted_quantity'], y=tmp['item_price']*(1-tmp["discount%"]), color='blue', label='APR')
# 12月の需要曲線
tmp = sales_by_date_and_category[(sales_by_date_and_category[product_grain]==category_num) & (sales_by_date_and_category["month"]==12)]
sns.regplot(x=tmp['predicted_quantity'], y=tmp['item_price']*(1-tmp["discount%"]), color='red', label='DEC')
plt.legend()
plt.title("Category ID=69")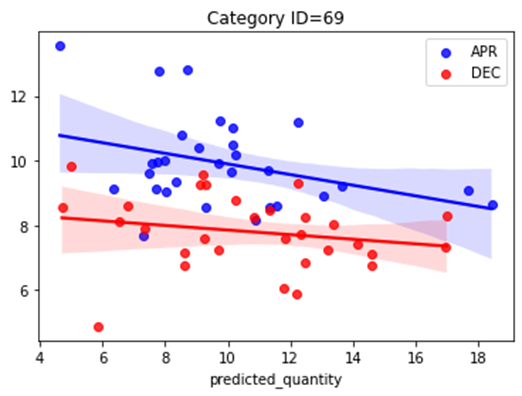
1.3.7 最適価格の算出
def optimize_quantity_out(model, df, product_grain, product_grain_value, day, month):
item_price_mean = df[df[product_grain] == product_grain_value].item_price.mean()
# get virtual prices
potential_price = np.linspace(item_price_mean * 0.25, item_price_mean * 2, 50)
# get virtual discounts
potential_discount = np.linspace(0, 0.4, 20)
# loop to create each combination of price and discount
samples = []
for d in potential_discount:
for p in potential_price:
sample = {
product_grain: product_grain_value,
'discount%': d,
'item_price': p,
'day': day,
'month': month
}
samples.append(sample)
# use trained model to predict on virtual samples
samples = pd.DataFrame(samples)
samples['q_out_pred'] = model.predict(samples)
samples['pFp'] = samples['q_out_pred']*(1-samples["discount%"])*samples["item_price"]
# tag optimal params
samples['is_optimal'] = [True if s == max(samples.q_out_pred) else False for s in samples.q_out_pred]
return samples# 4月20日の、カテゴリID69の最適価格を算出する
day = 20
month = 4
sku = 69
optimal = optimize_quantity_out(rf, sales_by_date_and_category, product_grain, sku, day, month)# ディスカウント率ごとの、価格と総売上高の関係
for rate in [0.0, 0.4]:
tmp1 = optimal[optimal['discount%']==rate]
plt.scatter(tmp1['item_price'], tmp1['pFp'], label=(f'DiscountRate {rate:.1%}'))
plt.legend()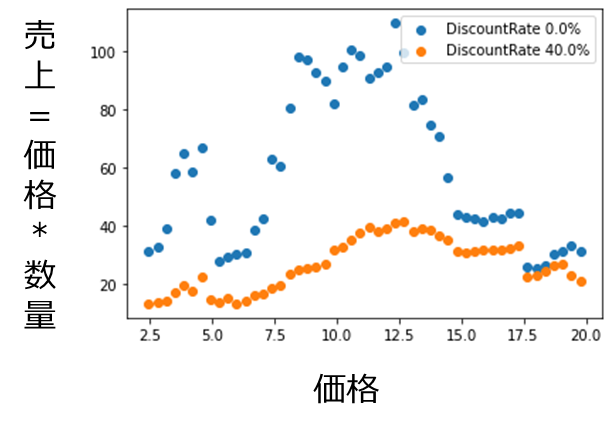
# カテゴリID 69番
# 4月の需要曲線
category_num = 69
tmp = sales_by_date_and_category[(sales_by_date_and_category[product_grain]==category_num) & (sales_by_date_and_category["month"]==4)]
sns.regplot(x=tmp['predicted_quantity'], y=tmp['item_price']*(1-tmp["discount%"]), color='blue', label='APR')
# 最適価格
D = optimal[optimal['pFp']==optimal['pFp'].max()][['discount%', 'item_price','q_out_pred']].values[0][0]
p = optimal[optimal['pFp']==optimal['pFp'].max()][['discount%', 'item_price','q_out_pred']].values[0][1]
q = optimal[optimal['pFp']==optimal['pFp'].max()][['discount%', 'item_price','q_out_pred']].values[0][2]
plt.scatter(q, (1-D)*p, color='red', label='Optimized point')
plt.legend()
plt.title("Category ID=69")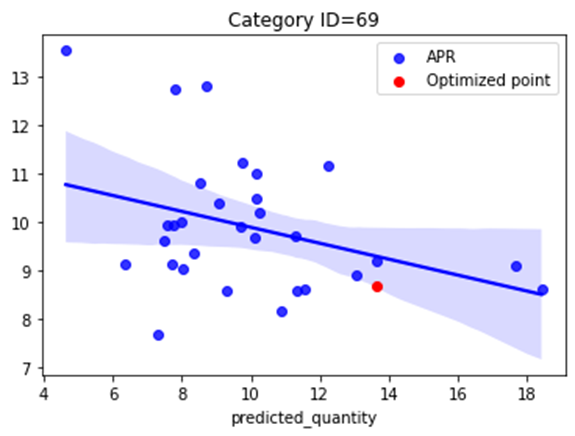
2. ダイナミックプライシングの懸念点
業種によっては、需要に応じて価格を上下させるような戦略は、顧客の足元を見ていると反発を招きます。3「Why Variable Pricing Fails at the Vending Machine」 NY times 2005.6.27 , https://www.nytimes.com/2005/06/27/business/why-variable-pricing-fails-at-the-vending-machine.html 高橋 「値決めの教科書」 (2023)
- 米国:飲料メーカーの例
変動価格自動販売機を検討。暑い日には需要が高くなるため、通常より高い価格で販売。
しかし、不当な値上げと捉えられ、消費者から反発を買う。すぐに撤退。
個人間の需要の強弱で価格を変更するのは、現実的ではないようです。前項でも述べてきたように、旅行・ホテル・イベント興行に限っては、消費者のコンセンサスを得やすいようです。
ご清聴ありがとうございました。