追記)
- 2023/3/16 「python仮想環境の」の節にuse_pythonの設定方法についてwindowsの場合を追記。
- なぜか、robyn_inputsのパートがまるまる抜けていたため(大変失礼しました)、それを追記。
Robynは、Meta社の便利なAutomated MMMツールです。更新は今でも続いており、2022年だけでも数回大幅にupdateされました。そのため、昨年書かれたこの記事の内容は古くなっており、現在この方法で実行すると2023年1月現在、エラーが発生するなどの問題があります。そこで、Robynを動かすための対症療法的な処方箋を共有します。なお、筆者は以下の作業をMacで行っています。Windowsでもほぼ同じで動作しますが、pathなどを適宜変更する必要があります。
目次
調査してわかったこと
- 記事通りに行うとRobynの最新版3.9.0がインストールされます。しかしこのバージョンはモデル構築時にエラーが出ます。(公式githubのチュートリアル通りでもエラーが出ます)
- 公式github通りにインストールすると、今度はなぜか3.7.2がインストールされます。しかし上記事象とは反対に3.9.0のほぼチュートリアル通りで*(一部引数を変えないといけない、後述する)上手くいきます。
対症療法
とにかく動くということを前提に、3.7.2という少し古いバージョンをインストールします。そのために以前の記事の最初の方の記述を変更します。
修正コード
Robynをremoteでgithubインストールしていた箇所を、通常のinstall.packageでインストールするように修正します。
ライブラリのインストール
元の記事の1番はじめのコードブロックを
# 作業ディレクト
setwd("./dev/MMM_02") # 今回の作業フォルダ前回は MMM_01
install.packages("Robyn") # install.packagesに変更
# remotes インストール
# install.packages('remotes')
# install
# remotes::install_github("facebookexperimental/Robyn/R")とします。あとは同じようにできる(はずですが)一応3.7.2版の仕様に合わせたコードを以下に記載します。使用するデータは元記事()と同じで、csvをgithubからDLできます。
残りのライブラリをインストールする。
# reticulate
install.packages("reticulate") # install.packagesは最初の一回のみでOK
library(reticulate)
# dplyr インストール
install.packages("dplyr")
library(dplyr)
# Robyn
library(Robyn)
packageVersion("Robyn")Python仮想環境
# pythonの環境を準備
virtualenv_create("r-reticulate")
py_install("nevergrad", pip = TRUE)
use_virtualenv("r-reticulate", required = TRUE)
use_python("~/.virtualenvs/r-reticulate/bin/python") # macではシェル起動時のディレクトリにある追記) use_python内に記述するpathは、ご自身の環境に合わせてください。上記は私のmacの場合です。windowsの場合はおそらく、R_workの下に.virtualenvsがあると思います。またbinではなくScriptsというフォルダ内にpython.exeというのがあるのではないかと思います。
データロード
以降は前回記事とほぼ同じです。記号の意味などはこちらを参照願います。
################################################################
#### Step 1: データ読み込み
dt_simulated = read.csv(file='sample.csv')
dt_simulated = dplyr::select(dt_simulated,datetime=1, Net.Spend=2 ,
Tv.Spend=3 ,temperature=4,
rain=5, revenue=6, Weekend.FLG=7,dplyr::everything())
head(dt_simulated)
data("dt_prophet_holidays")
head(dt_prophet_holidays)
# オブジェクト保存用のフォルダ指定 (ご自身の環境名に変更)
robyn_object <- "/Users/mitsuru_urushibata/dev/MMM_02/MyRobyn.RDS"データの準備 (2023/03 追記)
################################################################
#### Step 2a: モデル構築
#### 2a-1: 入力変数の指定
#input
InputCollect <- robyn_inputs(
dt_input = dt_simulated #入力する元データ
,dt_holidays = dt_prophet_holidays #祝日データ
,date_var = "datetime" # 以下のフォーマットで"2020-01-01"
,dep_var = "revenue" # 売上高やCVなどの従属変数
,dep_var_type = "revenue" # 売上高かCVフラグか
,prophet_vars = c("trend", "season") # "trend","season", "weekday" & "holiday"
,prophet_country = "US"# 国名 祝日 デフォルトで日本がないため一旦USとしておく
,context_vars = c("temperature", "rain", "Weekend.FLG") # イベント情報 adstock変換なし
,paid_media_spends = c("Net.Spend","Tv.Spend") # メディア投下
,paid_media_vars = c("Net.Spend","Tv.Spend") # メディア
# paid_media_vars must have same order as paid_media_spends. Use media exposure metrics like
# impressions, GRP etc. If not applicable, use spend instead.
#,organic_vars = c("newsletter") # PRなどの非広告メディア adstock変換あり
,factor_vars = c("Weekend.FLG") # contextとorganicで因子変数であるものを記載
,window_start = "2019-04-01" # モデル構築に使用するデータの開始日
,window_end = "2020-03-31" # モデル構築に使用するデータの終了日
,adstock = "geometric" # adstockの形状
)
print(InputCollect)
ハイパーパラメータの定義
#### 2a-2: ハイパーパラメータの定義
# 3.6.0からの追加 変数名変換のおまじない?
hyper_names(adstock = InputCollect$adstock, all_media = InputCollect$all_media)
#上記のハイパーパラメータの可変領域を設定
hyperparameters <- list(
Net.Spend_alphas = c(0.5, 3)
,Net.Spend_gammas = c(0.3, 1)
,Net.Spend_thetas = c(0, 0.3)
,Tv.Spend_alphas = c(0.5, 3)
,Tv.Spend_gammas = c(0.3, 1)
,Tv.Spend_thetas = c(0.1, 0.4)
)robyn_input()
#### 2a-3: Third, ハイパーパラメータをrobyn_inputs()に入力
InputCollect <- robyn_inputs(InputCollect = InputCollect, hyperparameters = hyperparameters)
print(InputCollect)
if (length(InputCollect$exposure_vars) > 0) {
lapply(InputCollect$modNLS$plots, plot)
}モデリング
################################################################
#### Step 3: モデル構築
OutputModels <- robyn_run(
InputCollect = InputCollect, # feed in all model specification
cores = NULL, # NULL defaults to max available - 1
iterations = 2000, # 2000 recommended for the dummy dataset with no calibration
trials = 5, # 5 recommended for the dummy dataset
ts_validation = FALSE, # 3-way-split time series for NRMSE validation.# 追加
add_penalty_factor = FALSE # Experimental feature. Use with caution.
)
print(OutputModels)
## パレート最適解を計算
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
pareto_fronts = 1, # ここはマニュアル通りではダメ automatically pick how many pareto-fronts to fill min_candidates
# min_candidates = 100, # top pareto models for clustering. Default to 100
# calibration_constraint = 0.1, # range c(0.01, 0.1) & default at 0.1
csv_out = "pareto", # "pareto", "all", or NULL (for none)
clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters
plot_pareto = TRUE, # Set to FALSE to deactivate plotting and saving model one-pagers
plot_folder = robyn_object, # path for plots export
export = TRUE # 追加機能 this will create files locally
)
print(OutputCollect)モデルを選択
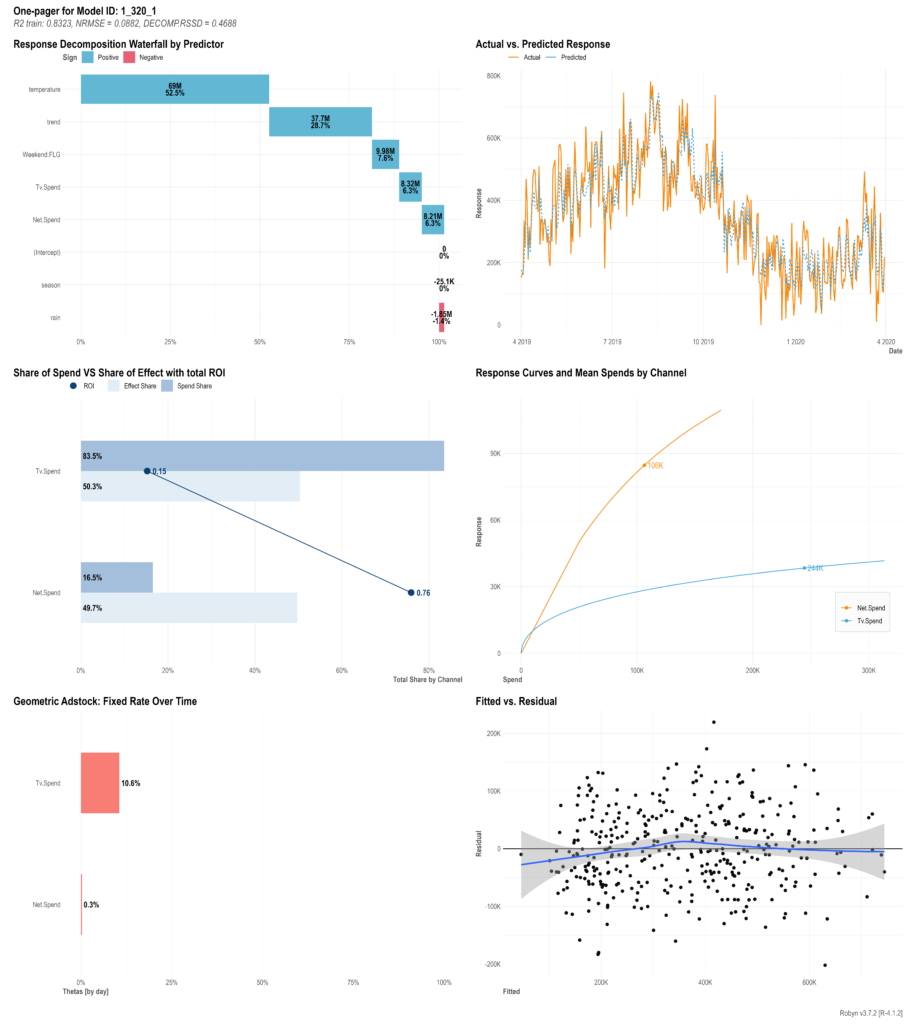
################################################################
#### Step 4: モデルを選択
## Compare all model one-pagers and select one that mostly reflects your business reality
print(OutputCollect)
select_model <- "1_320_1" # Pick one of the models from OutputCollect to proceed
#### Since 3.7.1: JSON export and import (faster and lighter than RDS files)
ExportedModel <- robyn_write(InputCollect, OutputCollect, select_model)
print(ExportedModel)予算のアロケート
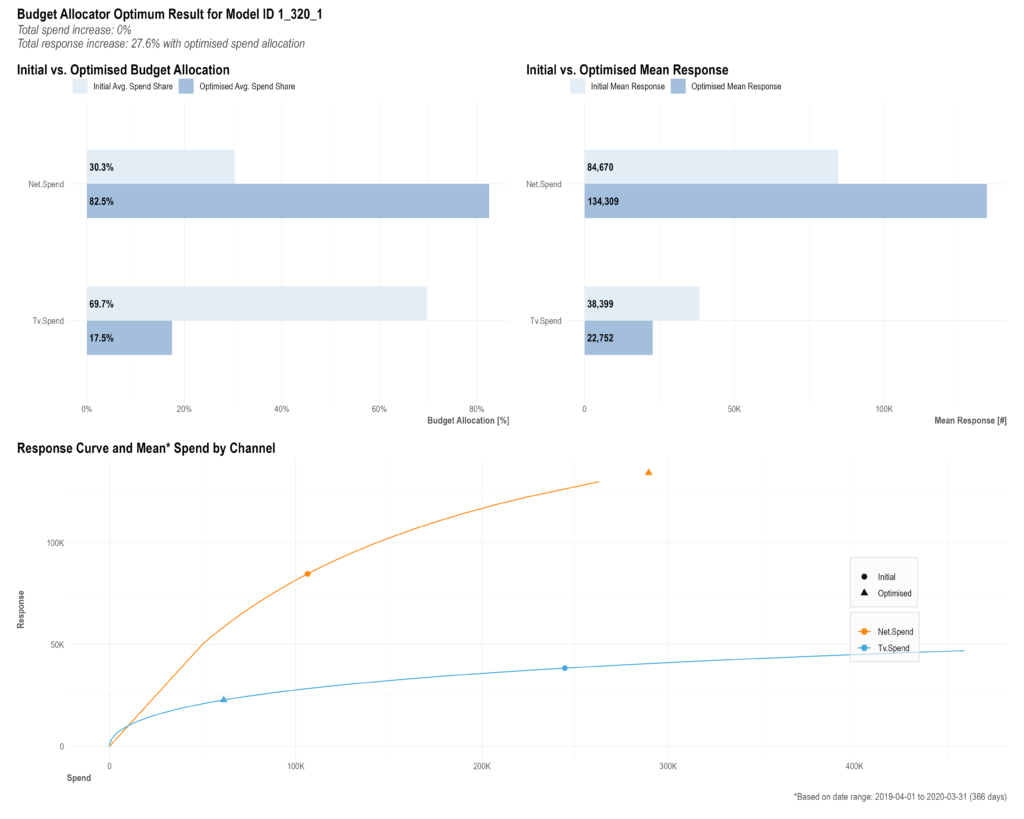
################################################################
#### Step 5: Get budget allocation based on the selected model above
AllocatorCollect1 <- robyn_allocator(
InputCollect = InputCollect,
OutputCollect = OutputCollect,
select_model = select_model,
scenario = "max_historical_response",
channel_constr_low = c(0.01, 0.01), #メディア数と同じ長さが必要
channel_constr_up = c(10, 10),
export = TRUE,
date_min = "2019-04-01",
date_max = "2020-03-31"
)
print(AllocatorCollect1)