以前このような記事を書きました。
Jupyter Notebooks上でGUI感覚でデータ解析を行う
2年もたち、仕様も色々変わたようです。従って改めて2021年版のbambolibチュートリアルを書きたいを思います。余談ですがdatabricks社の傘下に入ったようで、とりまくビジネス環境も変わってようです。databricks社はクラウドDWHやデータレイクなどの分析基盤プラットフォームを提供する会社です。
無料版はローカル環境、もしくはbinder上で実行可能です。以前はbinderからの実行に限られていたのですが、ローカル環境で実行可能になったことで非エンジニアの方にもとっつきやすくなったのではないでしょうか。そもそも私も含めて非エンジニアはgithubすらまともに使いこなせないため今回の変更はありがたいです。
ローカルで使用するため、インストールをします。Kaggle上でも使えるようですが、現在(2021/11)時点ではサポートしていないとのことです。
anaconda環境で使用することを前提に話を進めます。anacondaをインストールしていない方は適宜anacondaの公式サイトよりダウンロードしてインストールしてください。
環境とインストール構築
anaconda仮想環境を作成します。ターミナル上(windowsではanaconda prompt上)で
conda create -n bl python=3.7として環境を構築します。blは環境名なので任意で結構です。以降に出てくる「bl」は各自がつけた環境名に適当に変更してください。次に作成した環境をアクティブにします。
#アクティブにする
activate bl#ipykernelをインストール
conda install jupyter
conda install ipykernel
python -m ipykernel install --user --name bl
#bamboolibをインストール
pip install --upgrade bamboolib --user#たまにpip install やsetuptoolsが古いなどでエラーが出る場合はオプションで以下
pip install --upgrade pip
pip install --upgrade setuptools#jupyter notebookの拡張
python -m bamboolib install_nbextensionsjupyter notebookとコマンドにうちnotebookを立ち上げます。
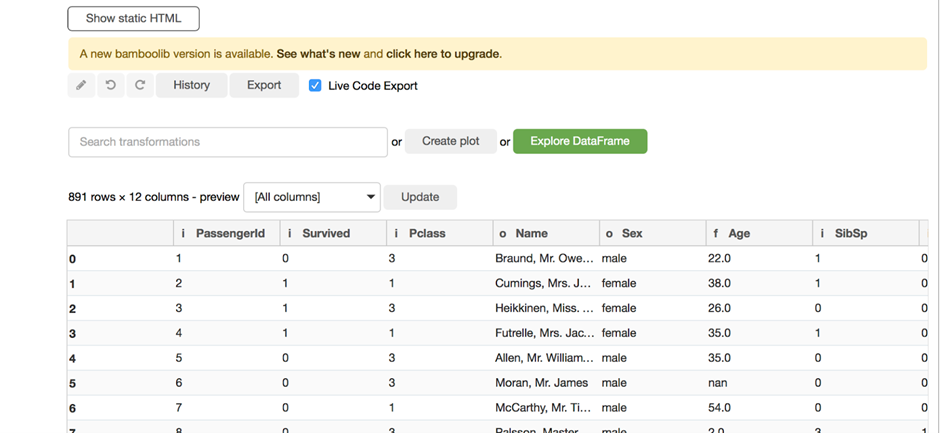
import bamboolib as bam
import pandas as pd
df = pd.read_csv(bam.titanic_csv)
display(df)と打ち込んで以下の画面が出れば成功です。