
2024年3月、GoogleはMMMツール「Meridian」をリリースしました。これは、以前から有名だったLightweight MMMの後継ツールとして位置づけられています。
いまいち流行ってないように見える?
しかしRobynほど普及していないように見えます。その理由として、ベイズモデリングの事前分布の概念が理解しづらいことや、地域階層モデルが重要な機能として挙げられているものの、日本のような比較的小さな国土では地域差がアメリカほど顕著でないため、その有用性が実感しにくいことが考えられます。
また、実行環境についてもGPUの使用が推奨されているのがハードルとなっています。GPUマシンを所有していても、Windowsの場合はTensorFlowの現行バージョンがWindows上のGPUをサポートしていないため実行できません。
そのため、GPUを利用するにはMacかLinuxで実行するか、有料版のGoogle Colab PROを使用する必要があります。
このような環境面での制約も、普及を妨げている要因の一つだと考えられます。
Windows PCでお手軽に試してみる
meridianは、NUTSサンプラーを使用するので、本来はGPU推奨…です。しかし、小規模なデータセットならCPUだけでも普通に動かせます!
まずは実際に動かしてみることが理解への第一歩です。そこで、WindowsのCPU環境での実行例をご紹介します。小規模なデータなら数分程度で計算が終わるので、気軽に試せます。
必要なものは以下の2つだけです:
- Anacondaという便利なPython環境(無料)
- Jupyter Lab(ブラウザ上でプログラムを書くための便利なツール)
これだけあればOKです。
環境構築
以下の構成での構築を目指します。
| 項目 | 内容 |
| OS | Windows 10 / 11 |
| 仮想環境管理 | Anaconda(conda) |
| Pythonバージョン | 3.11 |
| TensorFlowバージョン | CPU版 (2.16系) |
| Meridianバージョン | 1.0.1(2025年4月現在最新) |
ステップ1:Anacondaのインストール
まず、Pythonの環境を整えるために、Anacondaをインストールします。
- Anacondaの公式サイトからWindows版のインストーラーをダウンロードします。
- ダウンロードしたインストーラーを実行し、画面の指示に従ってインストールを完了させます。
これで、PythonやJupyter Labなどのツールが一括で導入されます。Anacondaがお手元にある方は上記の作業は不要です。以下が参考になります。
- Anacondaのインストール手順【写真付き手順】 #Python. Qiita. https://qiita.com/umashikate/items/4302340770ebd010af0b
- 【初心者向け】Anacondaインストールガイド:丁寧でわかりやすい手順解説. Zenn. https://zenn.dev/yogurt/articles/8933154b597d68 Zenn
ステップ2:作業用フォルダーの作成
- Anaconda Promptを起動します。
- プロンプト(黒い画面)に以下のように打ち込み作業フォルダを作成します。
(base) C:\Users\[あなたの名前]> mkdir meridian_project
(base) C:\Users\[あなたの名前]> cd meridian_project
一行ずつ打ち込み、エンターを押してください。黒い画面での操作は原則1行ごとにエンターでお願いします。
ステップ3:仮想環境の作成
Meridian用の仮想環境を作成します。
conda create -n meridian python=3.11 -y conda activate meridianこれにより、Python 3.11を使用する仮想環境が作成され、Meridianの動作に適した環境が整います。
ステップ4:必要なパッケージのインストール
仮想環境内で、Meridianとその依存パッケージをインストールします。
pip install --upgrade "google-meridian[and-cuda]"pip install jupyterlabconda install -c conda-forge notebook ipykernel上記も一行ずつエンターを押してください。
これで、MeridianとJupyter Labがインストールされます。
ステップ5:Jupyter Labの起動とMeridianの使用
Jupyter Labを起動し、Meridianを使用してMMMを実行します。
jupyter labと黒い画面に打ち込むエンターを押すと、ブラウザが立ち上がり以下の画面が出れば成功です。
ブラウザが自動的に開かない場合は、表示されたURLをコピーしてブラウザに貼り付けてください。
Jupyter Lab上で新しいノートブックを作成します。
以下のようにMeridianをインポートして使用します。ここからは黒い画面ではなくて、jupyter notebookのセルに記述していきます。1行ごとではなく1セルごとの実行が可能です。セルをアクティブにしてエンターを押してください。
import meridian
print(meridian.__version__)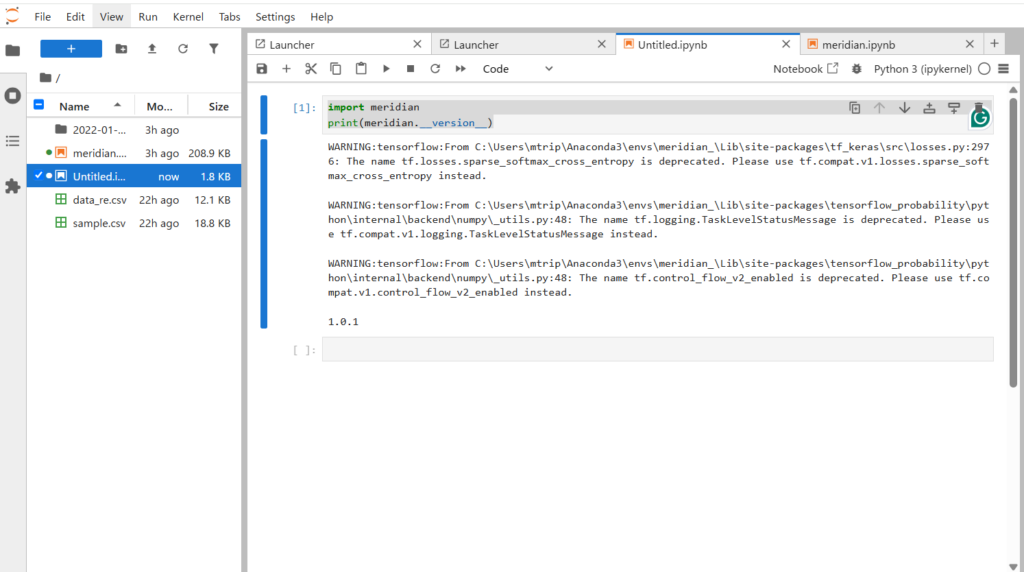
これで、Meridianのバージョンが表示されれば、インストールは成功しています。上記の図では1.0.1と出ています。
meridianを実行する(前編)
1. サンプルデータを準備
ここからdata_re.csvというデータをダウンロードして、先に作成した作業フォルダに入れます。
2. 必要なライブライリをimport
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_probability as tfp
import arviz as az
import IPython
# Meridianパッケージのモジュールをインポート
from meridian import constants
from meridian.data import load
from meridian.data import test_utils
from meridian.model import model
from meridian.model import spec
from meridian.model import prior_distribution
from meridian.analysis import optimizer
from meridian.analysis import analyzer
from meridian.analysis import visualizer
from meridian.analysis import summarizer
from meridian.analysis import formatter3. データの読み込みと加工
# ファイル名
csv_path = "data_re.csv"
# # CSVデータを読み込む(Pandas)
data = pd.read_csv(csv_path)
# # 日付をdatetime型に変換
# data['日付'] = pd.to_datetime(data['日付'])
# --- 日付整形(2024/1/1→2024-01-01に変更)
data["report_date"] = data["report_date"].str.replace("/", "-")
data["report_date"] = pd.to_datetime(data["report_date"])4. データカラムの設定
まずは、データセットの各列が何を意味するかをMeridianに教えるために、CoordToColumnsを設定します。
# CoordToColumnsの設定
coord_to_columns = load.CoordToColumns(
time='report_date', # 日付の列名
controls=[], # コントロール変数(今回は無しなら空リスト)
kpi='cv', # 成果変数名
revenue_per_kpi=None, # KPIが収益ではないのでNone
media=[
'google_search_budget',
'google_display_budget',
'yahoo_display_budget',
'meta_ads_budget'
],
media_spend=[
'google_search_budget',
'google_display_budget',
'yahoo_display_budget',
'meta_ads_budget'
],
# organic_media=[] # オーガニック施策は今回無し(空リストなら省略)
)ここでKPIを「cv(コンバージョン数)」にしている点に注目、使用するデータのカラムが「conversion」であればそれを入れてください。今回のデータでは「cv」です。
5. メディアチャネルのマッピング
続いて、各支出項目をチャネル名に変換するためのマッピングを定義します。
# メディアとチャネルのマッピング
media_to_channel = {
'google_search_budget': 'Google Search',
'google_display_budget': 'Google Display',
'yahoo_display_budget': 'Yahoo Display',
'meta_ads_budget': 'Meta Ads'
}
media_spend_to_channel = {
'google_search_budget': 'Google Search',
'google_display_budget': 'Google Display',
'yahoo_display_budget': 'Yahoo Display',
'meta_ads_budget': 'Meta Ads'
}6. データローダーの作成と読み込み
ここでデータをMeridian内部形式に変換します。
# --- データローダーの作成
loader = load.DataFrameDataLoader(
df=data, # 読み込んだDataFrameを渡す
kpi_type='non_revenue', # KPIが収益型じゃない(コンバージョンなので)
coord_to_columns=coord_to_columns,
media_to_channel=media_to_channel,
media_spend_to_channel=media_spend_to_channel
)
# --- データの読み込み
# datetime型でないとエラーが出るので注意
data = loader.load()7. 事前分布(Prior)の定義
モデルに入れるパラメータに対して事前分布を設定します。
# 事前分布の定義
prior = prior_distribution.PriorDistribution(
beta_m=tfp.distributions.HalfNormal(
scale=0.2, # HalfNormal 分布のスケール(標準偏差)を0.2に設定
name=constants.BETA_M # パラメータ名を設定
)
)8. モデル仕様(ModelSpec)の作成
事前分布を組み込んだモデル仕様を作成します。
model_spec = spec.ModelSpec(prior=prior)モデル本体を作成します。
mmm = model.Meridian(input_data=data, model_spec=model_spec)ここで初めてmmmオブジェクトが生成されます!
meridianを実行する(後編)
1. 事前分布のサンプリング
まずは、事前分布からサンプルしてモデルの初期挙動を確認します。
%%time mmm.sample_prior(500)- 500個サンプルします。
- 実行時間も計測(%%time)
2. 事後分布のサンプリング(本番推論)
本格的に事後分布(posterior)をサンプリングします。
mmm.sample_posterior(n_chains=7, n_adapt=500, n_burnin=500, n_keep=1000, seed=1)- チェーン数:7
- チューニング:500ステップ
- バーニン(捨てサンプル):500ステップ
- 保存サンプル数:1000
- シード固定(再現性確保)
3. 推論の収束を診断する(R-hatプロット)
推論がちゃんと収束しているか確認します。
model_diagnostics = visualizer.ModelDiagnostics(mmm)
model_diagnostics.plot_rhat_boxplot()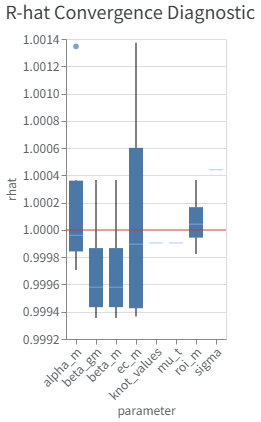
R-hatが1.1未満ならほぼOK!
4. モデル適合度を可視化する
モデルが観測データにどれくらいフィットしているかをプロットします。
model_fit = visualizer.ModelFit(mmm) model_fit.plot_model_fit()実測値と予測値のズレを直感的に確認します。
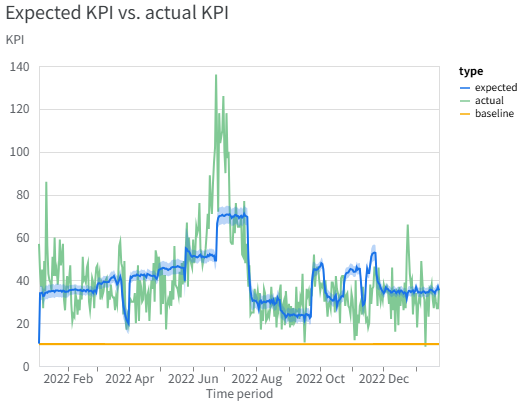
季節性などを入れていないため、周期などを捉え切れていないようです。
5. モデル結果をサマリー出力
最終的な分析結果をHTMLファイルに保存します!
mmm_summarizer = summarizer.Summarizer(mmm)
start_date = '2022-01-04'
end_date = '2023-01-23'
mmm_summarizer.output_model_results_summary('summary_output.html', start_date, end_date)HTML形式なので、ブラウザで手軽に閲覧・共有できます!
中身は各自ご確認をお願いします。
次回やりたいこと
今回はとにかく、Windowsローカルで実行するということをしました。今後は①「WSL2 (Windows Subsystem for Linux)上にLinux環境作ってTensorFlow 2.16.2 GPU版使う」を試す、さらに②実務上のハイパーパラメータの事前分布の設定や出力の味方を説明などをしたいと思います。