
レコメンデーション概要
ユーザの購買履歴などを元に、そのユーザに適した商品を推薦するシステムです。
Webコンテンツサービスや、ECのようなサービスに多くの事例があります。
事例1 Netflix
ユーザが視聴するコンテンツの75%は、パーソナライズされた商品のレコメンデーションによるもの。
事例2 Alibaba
2015年の第1四半期から2016年の第1四半期までの1年間で、機械学習を活用したレコメンドシステムが同社の商品総量(GMV)の売上に与える影響が3倍以上になり、2016年には5兆ドルを超えた。
いずれも1MIT Sloan Managemant Revie
[The Transformational Power of Recommendation] https://sloanreview.mit.edu/article/the-transformational-power-of-recommendation/を参考。
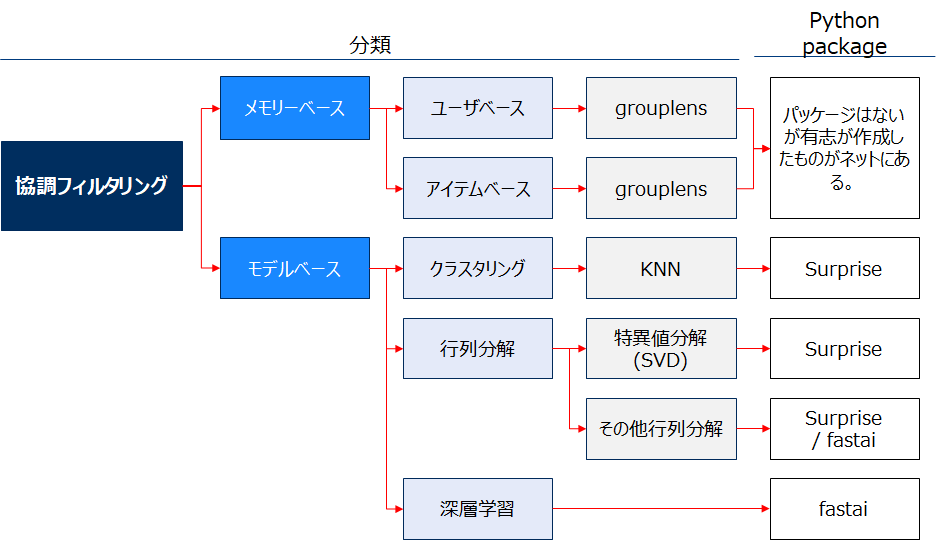
一般的な分類を2https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe03https://medium.com/@jwu2/knowledge-based-recommender-systems-an-overview-536b63721dba4https://medium.com/@jwu2/types-of-recommender-systems-9cc2162948025神嶌敏弘 2016 [推薦システムのアルゴリズム] https://www.kamishima.net/などを元に作成参考にし、本稿では大きく以下の4つに分類しました。

協調フィルタリングはその手法の違いによりさらに深く分類できます。
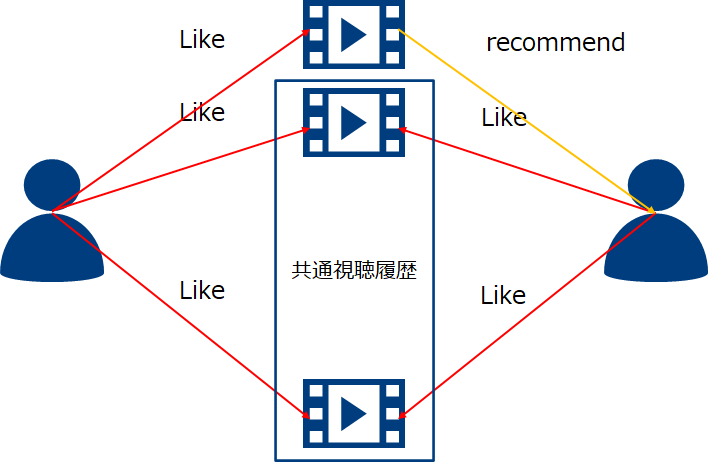
協調フィルタリングは自分の履歴のみならず他のユーザの履歴と組み合わせて評価予測を行います。
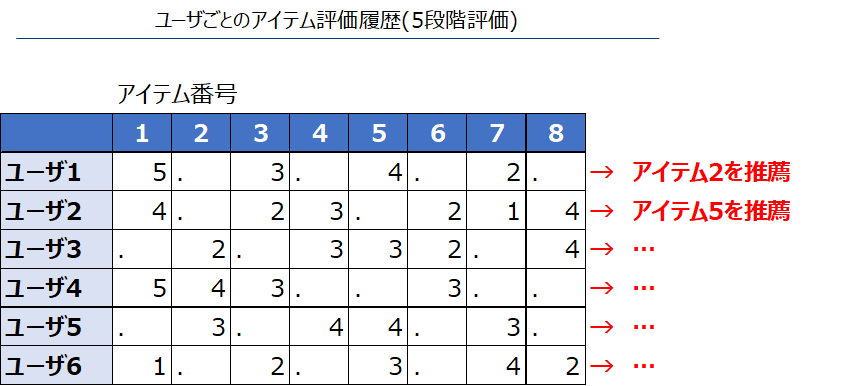
対象となるデータセット
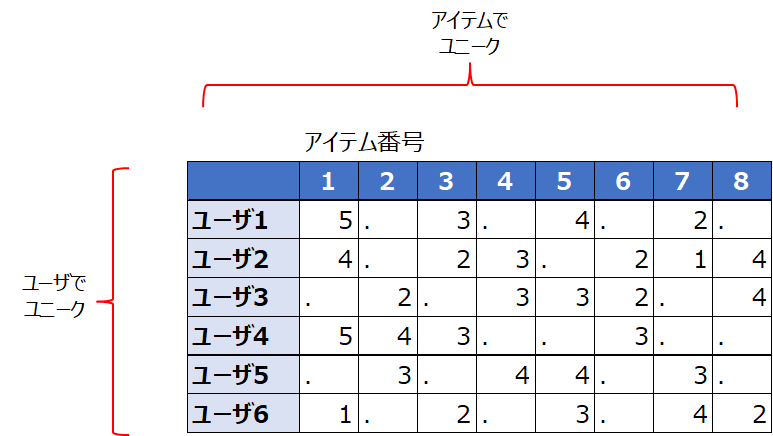
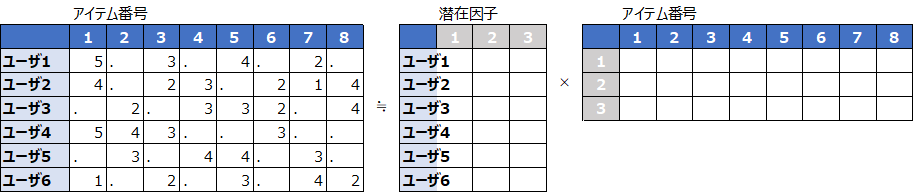
一般的にレコメンデーションに使用するデータセットはユーザを行、購買(視聴)したアイテムを列とする横長形式です。
i行目のj列目の値はi番目のユーザのj番目にアイテムに対する評価や購買(視聴)有無の値を設定します。
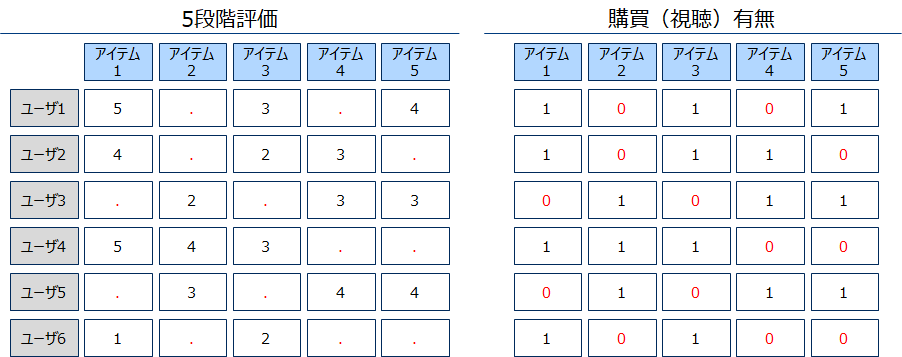
横長データ(下左図)
WebコンテンツやECなどフィードバックが得られやすいものに向いている形式です。一方で購買(視聴)無しを「0」とするのではなく欠損とするため、欠損処理を要したり、それを扱えるアルゴリズムに限定されるなどの制約がかかります。
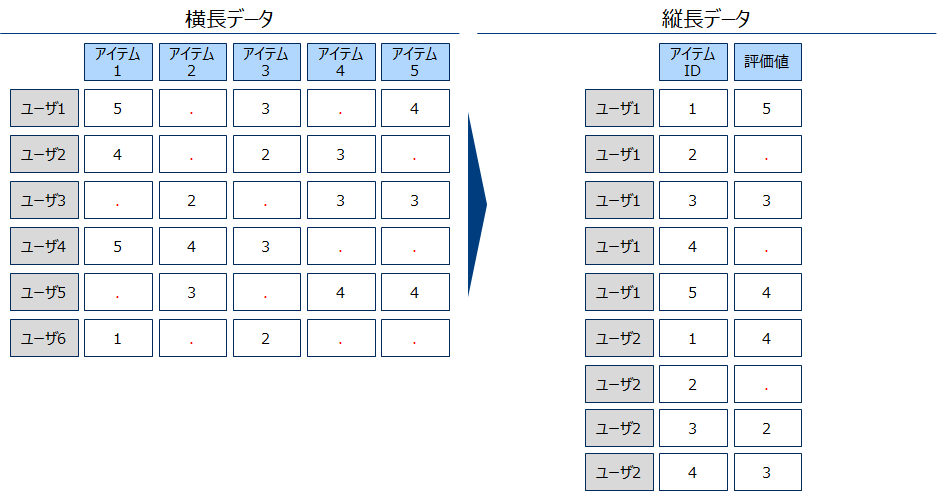
縦長データ(下右図)
この形式はレガシーな業界やオフライン売買のデータに向いています。例えば金融商品の販売状況や、住宅、自動車保有状況などです。
次節以降で使用するSurpriseパッケージは右下図のような縦長データを利用します(アイテムが多いため縦長の方が持ちやすい)。そのため前項の横長データを縦長にするpivotの逆操作のような変換を行います。
レコメンデーション実践
モデルベース協調フィルタリングを例に実践を行います。はじめにSurpriseを用いた手法を、最後にfastai6本稿ではSurprise マニュアル https://surprise.readthedocs.io/en/stable/index.html を主に参考にしたを用いた手法を紹介します。
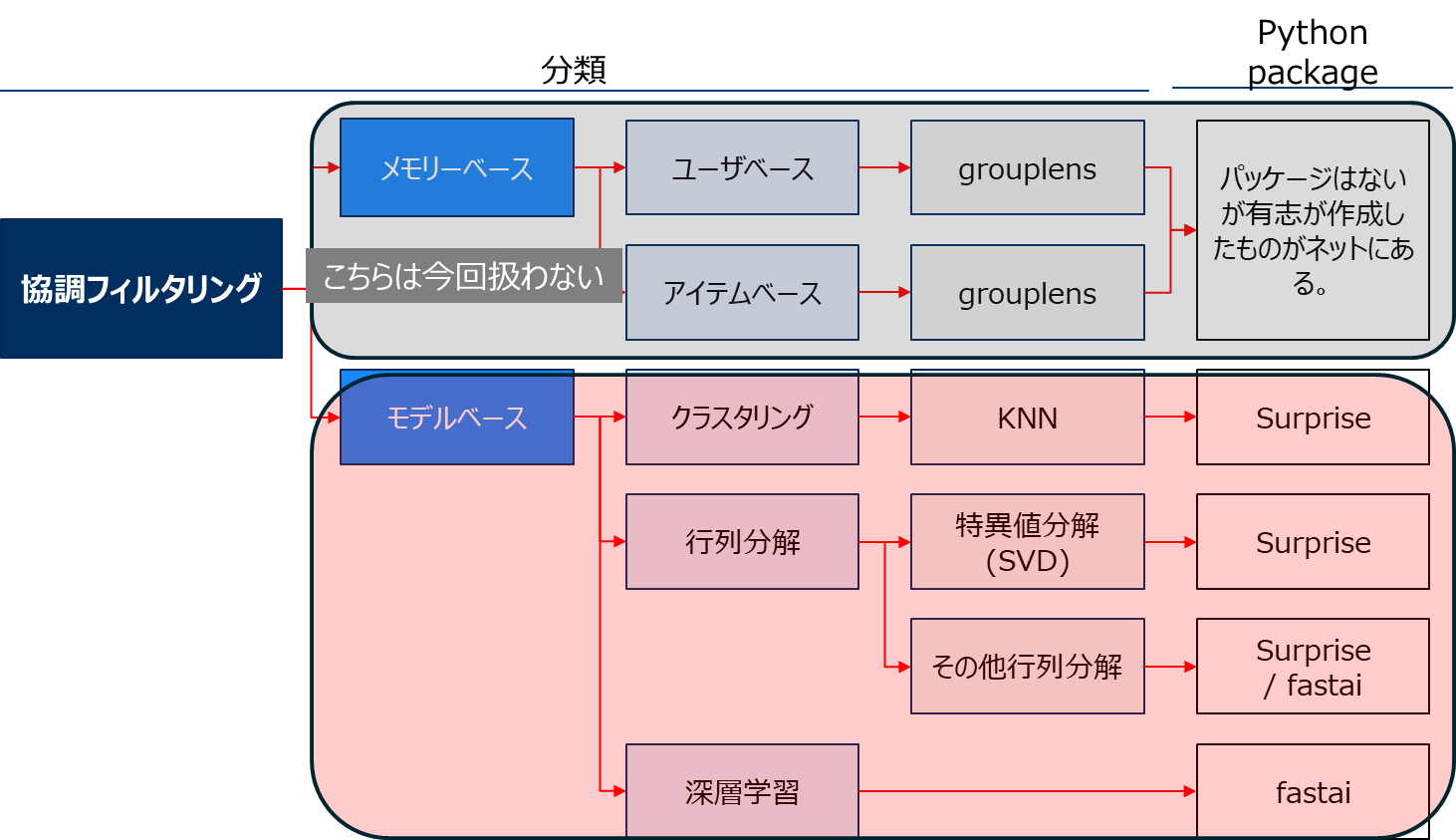
Surprise
pythonのSurprise(Simple Python RecommendatIon System Engine) パッケージを用いて実践を行います。以降のpgmはgoogle coloboratory上で動作確認しております。
#インストール coloboratory上では先頭に!を付ける
!pip install surprise#関連パッケージを読込む
from surprise import SVD
from surprise import NMF
from surprise import Dataset
from surprise import KNNBasic
from surprise.model_selection import cross_validate
from surprise.model_selection import train_test_split
from surprise import accuracy
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
rmse_dic = {}
scored_dic = {}MovieLens71997年にミネソタ大学のGroupLens研究室によって集められた映画の評価に関するデータ。8,500作品に対する1,100万のレーティングからなる。Surpriseライブラリから直接ロードすることができる。 ここでは10万件のレーティングを使用する。https://movielens.org/データを用いて映画のレーティングから適した推薦を推薦するシステムを構築します。
data = Dataset.load_builtin('ml-100k')
data.raw_ratings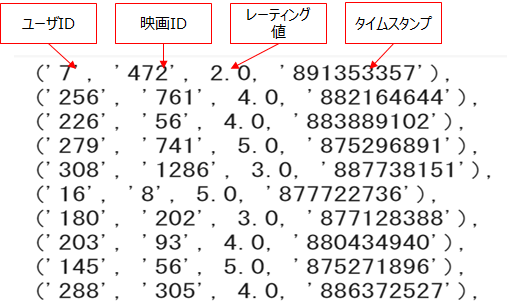
KNN法
KNN法は評価値を推定したい対象ユーザと良く似たグループ内での平均的評価を元に、その値を推定する方法です。8説明を省いたがメモリベース法であるGroupLensに近い手法です。
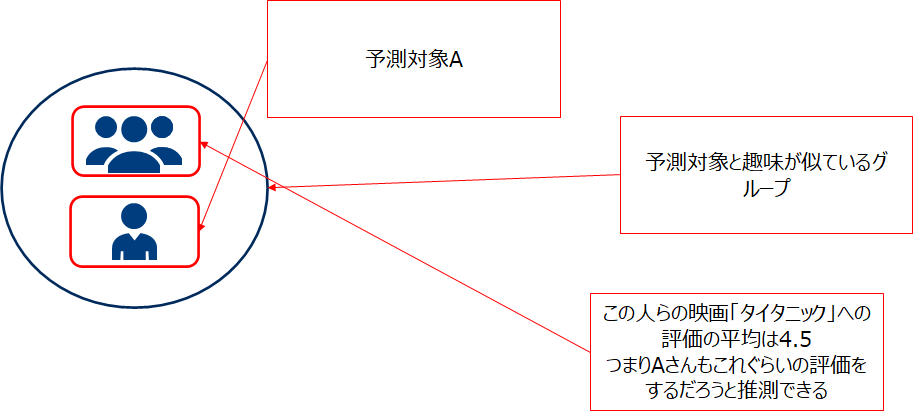
訓練データで学習をして検証データに当てはめてみます。
#訓練、検証データに分割する
trainset, testset = train_test_split(data, test_size=.25,random_state=123)
#学習
algo = KNNBasic() #KNNクラス作成
algo.fit(trainset)
#予測
predictions = algo.test(testset)
temp = pd.DataFrame([pred[0:4] for pred in predictions],columns=['UserID','ItemId','TrueRating','推測値'])
#例
display(temp)
scored_dic['KNN'] = temp
#平方平均2乗誤差
print (accuracy.rmse(predictions))
rmse_dic['KNN'] = accuracy.rmse(predictions)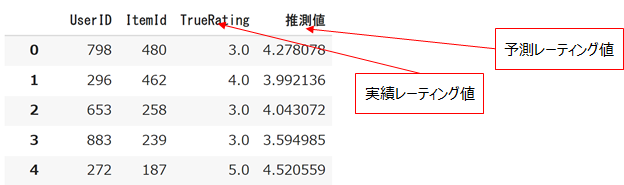
行列は一般的に特異値分解という表現を持ちます。与えられたユーザ×アイテム行列をこの表現で近似する手法を学習します。

実際は欠損があるデータを特異値分解(SVD)することはできないため、観測されているデータのみを用いて要素同士の誤差が最小になるように、右側の行列の要素を学習します。SurpriseではSimon Funkの手法が実装されています。9https://surprise.readthedocs.io/en/stable/matrix_factorization.html#surprise.prediction_algorithms.matrix_factorization.NMF https://medium.datadriveninvestor.com/how-funk-singular-value-decomposition-algorithm-work-in-recommendation-engines-36f2fbf62cac
SVD法
SVD法もほぼ同じように記述できます。
#学習
algo = SVD()
algo.fit(trainset)
#予測
predictions = algo.test(testset)
temp = pd.DataFrame([pred[0:4] for pred in predictions],columns=['UserID','ItemId','TrueRating','推測値'])
#例
display(temp)
scored_dic['SVD'] = temp
#平方平均2乗誤差
print (accuracy.rmse(predictions))
rmse_dic['SVD'] = accuracy.rmse(predictions)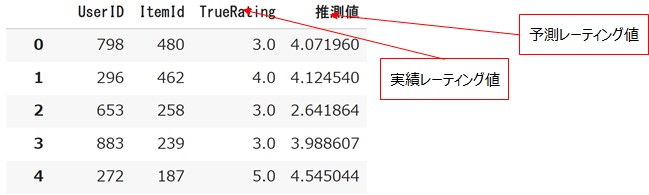
NMF法
特異値分解と同じように行列を分解する手法であり、こちらは要素が非負である2つの行列に分解します。
SVDと同様に欠損があるため観測されている要素同士の差を計算し、||A-WH||を最小にする、非負行列を学習します。
SVDやKNNとほぼ同じように書けます。
#学習
algo = NMF()
algo.fit(trainset)
#予測
predictions = algo.test(testset)
temp = pd.DataFrame([pred[0:4] for pred in predictions],columns=['UserID','ItemId','TrueRating','推測値'])
#例
display(temp)
scored_dic['NMF'] = temp
#平方平均2乗誤差
print (accuracy.rmse(predictions))
rmse_dic['NMF'] = accuracy.rmse(predictions)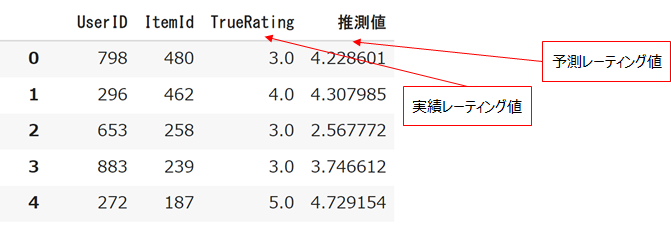
RMSEスコア比較をすると、SVDのスコアが最も良いという結果でした。
for k,v in rmse_dic.items():
print (k,v)
fastai
fastaiはPytorchをバックエンドとして使用する深層学習パッケージである。fastaiは主に2つの協調フィルタリングの手法を持ちます。
 共通の処理として関連ライブラリをインポートします。なお使用するデータはSurpriseの時と同じであるが、データフレーム形式に変換しておきます。
共通の処理として関連ライブラリをインポートします。なお使用するデータはSurpriseの時と同じであるが、データフレーム形式に変換しておきます。
from fastai import *
from fastai.collab import *
from sklearn.model_selection import train_test_split
from surprise import Dataset #dastasetという名前が衝突するため最後にimportする
#Supriseと同じデータを使用する
data = Dataset.load_builtin('ml-100k')
df = pd.DataFrame(data.raw_ratings,columns=['UserID','ItemID','Rating','Timestamp'])
display(df.head())
train ,test = train_test_split(df,test_size=0.25,random_state=12345)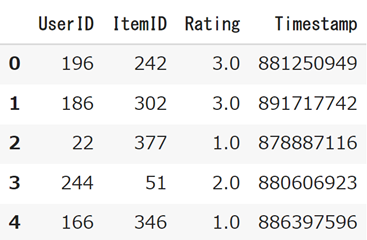
EmbeddingDotBias
#データセットをCollabdataBunchで使用できるように変換
data = CollabDataBunch.from_df(train, test = test, bs=512) #Pandas データフレームからfastai用のデータに変換
#data.show_batch()
learn = collab_learner(data, n_factors=50, y_range=(1, 5)) #潜在因子=50個としてレーティング値の範囲を1-5とする。
print (learn.model)
learn.fit(4)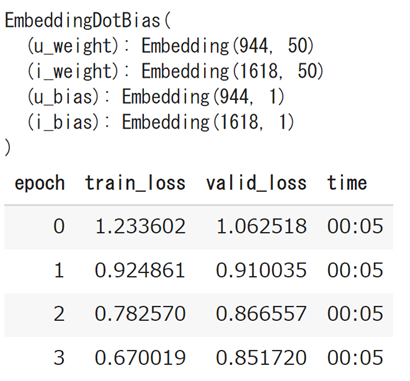
#RMSE計算
tensor = learn.get_preds(ds_type=DatasetType.Test)[0].numpy()
rmse_dic['fastai_dot'] = np.mean((test['Rating']-pd.Series(tensor,index=test.index))**2)**(1/2)
display(pd.concat([test['Rating'],pd.Series(tensor,index=test.index)],axis=1).head())
print (rmse_dic['fastai_dot'])
EmbeddingNN
#データセットをCollabdataBunchで使用できるように変換
data = CollabDataBunch.from_df(train, test = test, bs=512)
#data.show_batch()
#use_nn=Trueとすることでnnモードになる潜在因子の指定は不要そのかわり、Layersを指定する。
learn = collab_learner(data, use_nn=True, y_range=(1, 5),layers=[300,50])
print (learn.model)
learn.fit(4)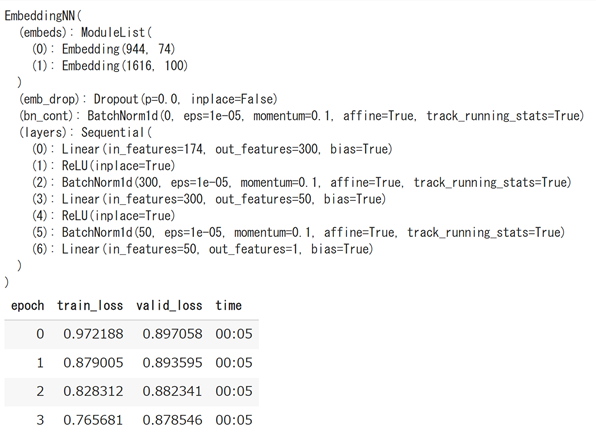
#RMSE計算
tensor = learn.get_preds(ds_type=DatasetType.Test)[0].numpy().squeeze()
rmse_dic['fastai_nn'] = np.mean((test['Rating']-pd.Series(tensor,index=test.index))**2)**(1/2)
display(pd.concat([test['Rating'],pd.Series(tensor,index=test.index)],axis=1).head())
print (rmse_dic['fastai_nn'])
全体比較
import matplotlib.pyplot as plt
#全体の精度比較
print (rmse_dic)
for k,v in rmse_dic.items():
plt.bar(k,v)
plt.title("RMSE")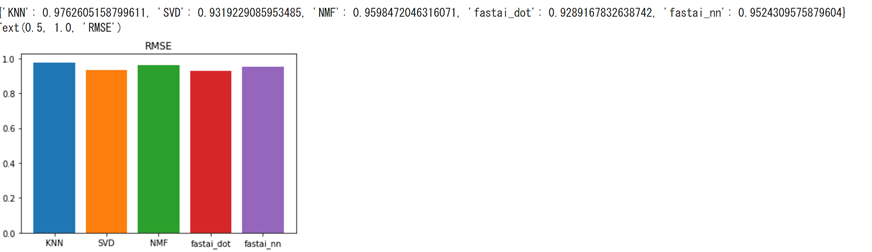
当然ですがデータが変われば、それぞれの手法の精度の序列は分かります。適宜データに合わせて手法は柔軟に変えていく必要があります。
以上です、ご精読ありがとうございました。