
こちらで、最近のデータ基盤動向についてまとめました。本稿では特にGoogle Cloud Platformに焦点をあて、データ基盤構築の実践を行っていきます。
Google Cloud Platform
Google Cloud Platform(GCP)は世界シェア3位ながら、成長率が高く、特にオンライン広告との相性が良い。また機械学習において他の2つより評価されています。1https://www.canalys.com/newsroom/global-cloud-market-Q121

IaaS/PaaS/SaaS/FaaS全部で100種類以上のサービスを持ちます。 データ基盤に関係ありそうなものをまとめました。

その他にも、pub/sub、dataprep dataproc cloud functions、などがありますが、簡単な構成を作成する最低限のものを記しました。
実践 Biq Queryにデータ作成
データをバッチで取込、加工、可視化を行う基盤を構築してみます。
やりたいことは、筆者が個人的に毎日収集している、海釣り施設の釣果情報をCloud Storageにアップし、バッチ(ストリーミングでもできるが)でBigQueryに連携。BIに加工連携し日時、場所、魚の種類ごとの釣果情報を可視化することです。
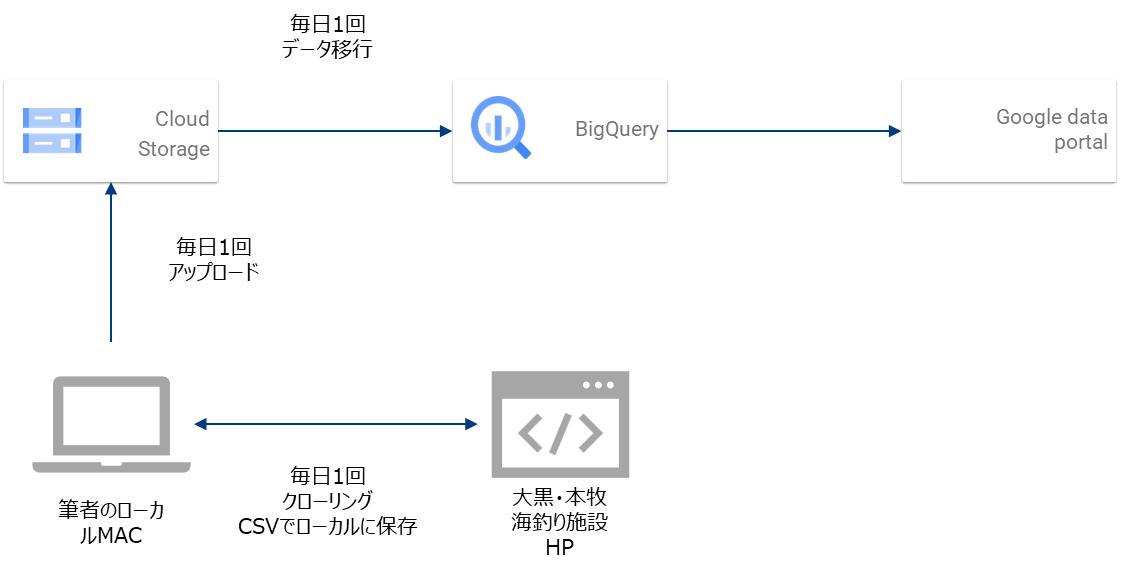
まず、過去分のデータをBigQuery(BQ))に取込むことから行い、そのあとバッチ処理のパイプラインを構築すし、最後にBIへの連携部分を作成します。
- GCPにプロジェクト作成 (Gsuiteアカウントがあり、組織独自ドメインがあることを前提)
- 請求先アカウント作成→プロジェクトの費用を紐づける
- Cloud SDK インストール→ローカルmac端末のshell上からGCSを操作するための、gsutilコマンド、BQを操作するためのbqコマンドを使用できるようにする。
- Python用クライアントライブラリをインストール→ローカルmac端末からGCS→BQという操作をpythonで書けるようにするために必要。
- サービスアカウント設定→Pythonクライアントの実行のために必要(認証の問題)
- Cloud Storageのバケット作成→バケットはcloud shell(glの管理画面)からGUIで行う。
- BigQueryテーブル作成→BQコマンドを使用する。
- 過去分(5年分)をStorageに取込み(gsutilコマンド)、作成したBigQueryのテーブルに追加していく。(クライアントライブラリを使用)
- Google data portal と連携し可視化。
- 毎日のバッチ処理を作成する。(クライアントライブラリを使用)
正直色々なやり方がありますが、バッチ処理しやすいようにコマンドライン操作とpythonで処理する方法にしました。
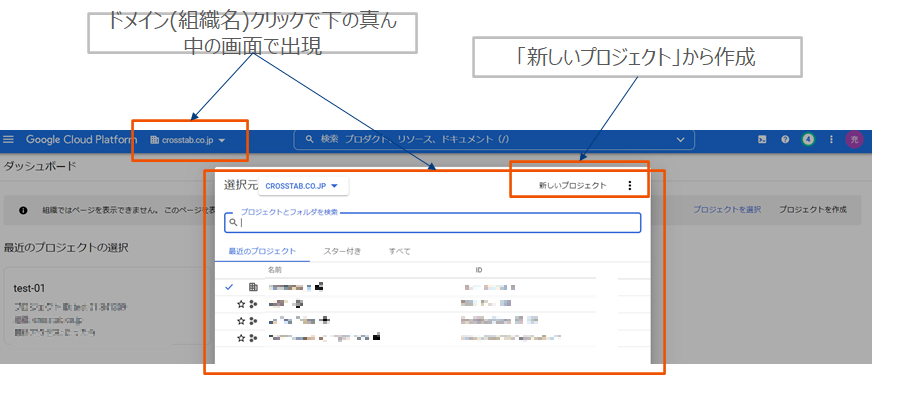
プロジェクト作成
プロジェクトを作成します。組織(ドメイン)というカテゴリの下に紐づくイメージです。
Googleworkspace(旧Gsuite)にアカウントがあることが前提。不明であれば情報システムやインフラ開発部門に問い合わせましょう。個人で実行したい場合は、個人のgmailアカウントがあれぼ良いようです。
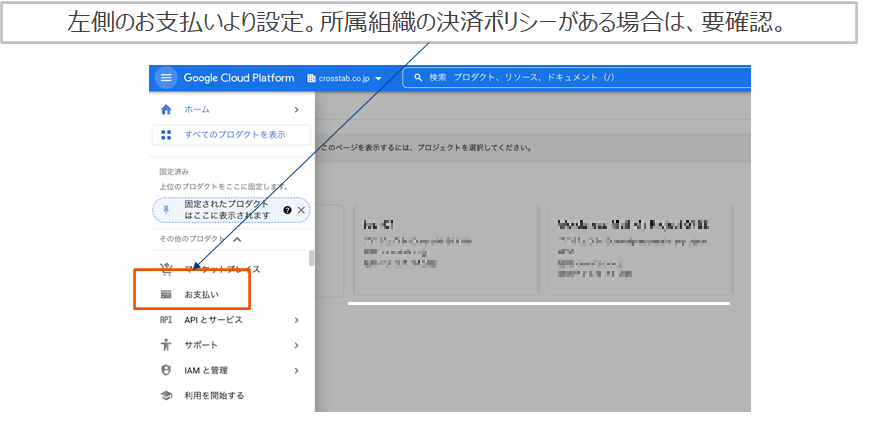
請求先アカウント作成
請求先アカウントを作成し、プロジェクトに紐づける。
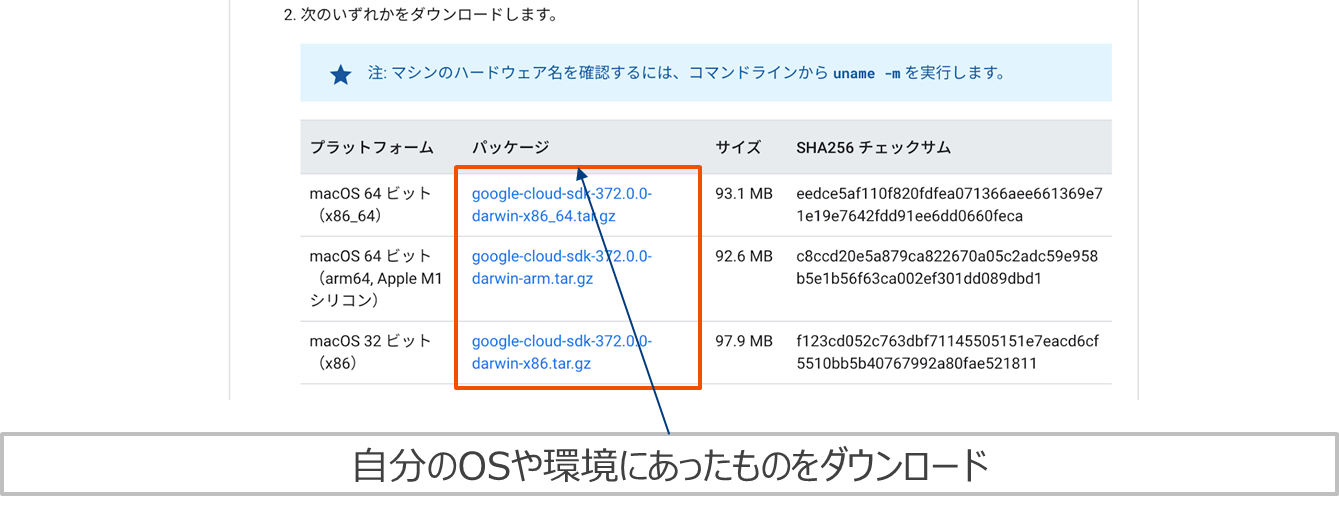
Cloud SDKインストール
https://cloud.google.com/sdk/docs/install?hl=ja#mac からCloud SDKをダウンロードしてローカルマシンにインストール。
(参考) 手順 Cloud SDKインストール (参考) 細かい手順 (Mac版)
①ダウンロードした、tarを解凍→google-cloud-sdkという名前のフォルダができる。
②そのフォルダがある、ディレクトリで、macのシェルから以下のように打ち込む。
./google-cloud-sdk/install.sh③y/n と聞かれるので「y」と入力。 python3.7がない場合ダウンロードしてくれます。
④gcloud init を実行して SDK を初期化します。
./google-cloud-sdk/bin/gcloud init⑤これを実行するとurlの出力があり、そのurlをコピーしてブラウザにペースとしてアクセスします。googleのアカウントの認証とsdkのアクセスの許可画面が出ますので、許可してください。そのあと画面にでた文字列トークンをコピーしshellに打ち込んでください。
⑥ものすごい長い文字列の出力が終わったあと。シェルを再起動する。再起動しないと有効にならない。
⑦これでgsutilコマンド、bqコマンドが使用可能になった。
Python用クライアントライブラリをインストール (Mac版)
macのシェルターミナル上で行います。
①Virtualenvでクライアントライブラリ用のpython仮想環境を構築(別に必須ではないが、pythonマナーとしてこうするのが定石)
pip install virtualenv # virtualenvをインストール
virtualenv -p python3.7 bq # インタプリタをpython3.7で指定して「bq」という名前の仮想環境を作成②作成した仮想環境をアクティブにする。
source bq/bin/activate # 作成した環境[bq]をアクティブにする。③Google-cloud-bigqueryをアップデート
pip3 install --upgrade google-cloud-bigqueryサービスアカウント設定
- https://cloud.google.com/docs/authentication/production?hl=ja を参考にjsonファイルのキーを作成。
- Jsonファイルをローカルのどこかに置く。(例えば作成したbq環境のフォルダ下など)
- 以下のように打ち込む。(shellを立ち上げるたびに必要) ******は①作成したjsonファイル名、/Users/[user名]/bq/はjsonファイルが置いてある場所。
export GOOGLE_APPLICATION_CREDENTIALS="/Users/[user名]/bq/*******.json"サービスアカウントにロールを与える。ここではCloud StorageとBQが使えるようにしておきます。
bigqueryとGCSに対してのロールを与えておきます。ロールの追加は以下から行います。
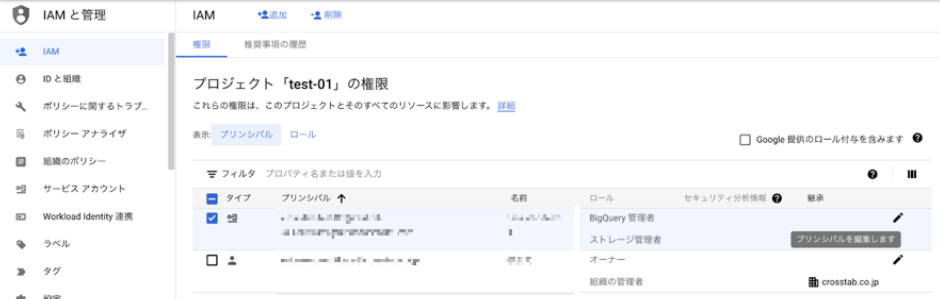
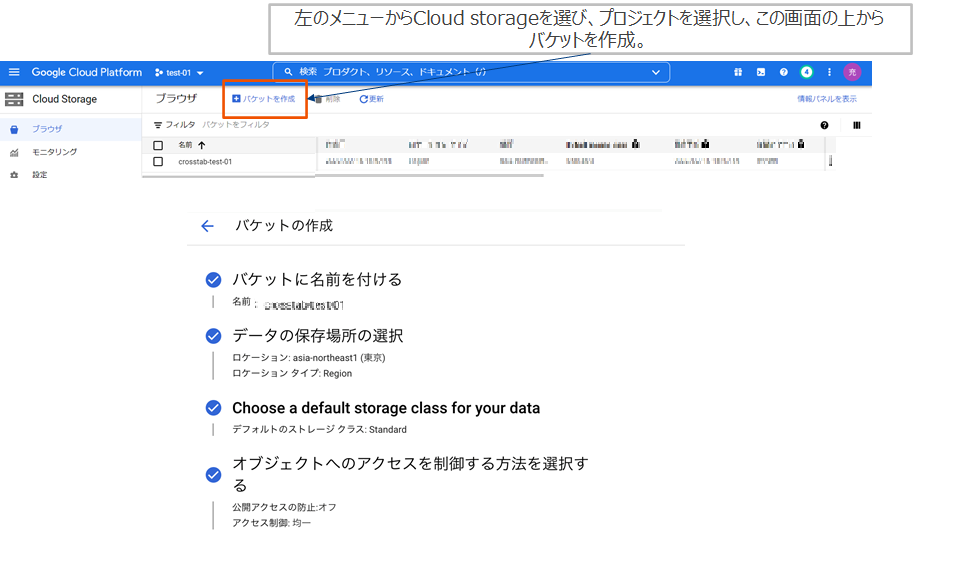
Cloud Storageのバケット作成
StorageはAWSS3と同様にバケットという単位で扱います。バケットの中にフォルダを作成できます。
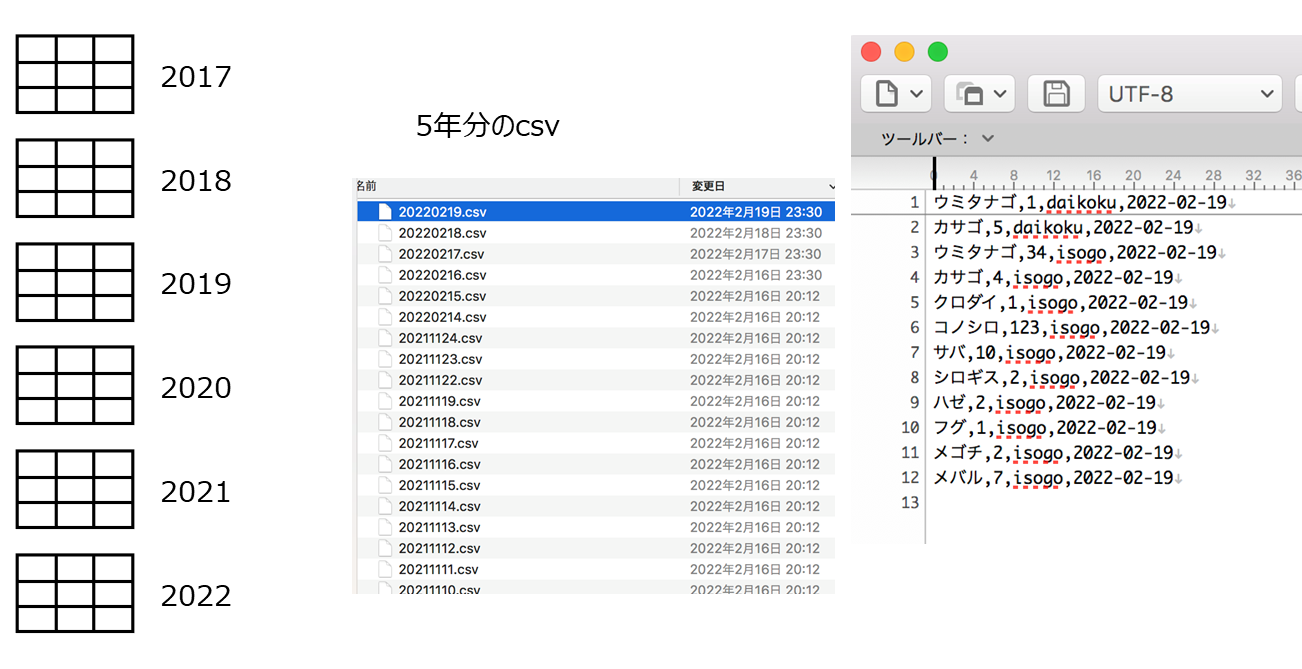
BigQueryテーブル作成
取り込みたいデータの形は右下です。これが5年分日次である(いくつか取得できていない日もあるが)。
そのため年ごとに同じ形をしたテーブルを作成します。
プロジェクトの下にデータセット、その下にテーブルが紐づきます。そのため先にデータセットを作成。これはcloud shellのGUI画面から行います。
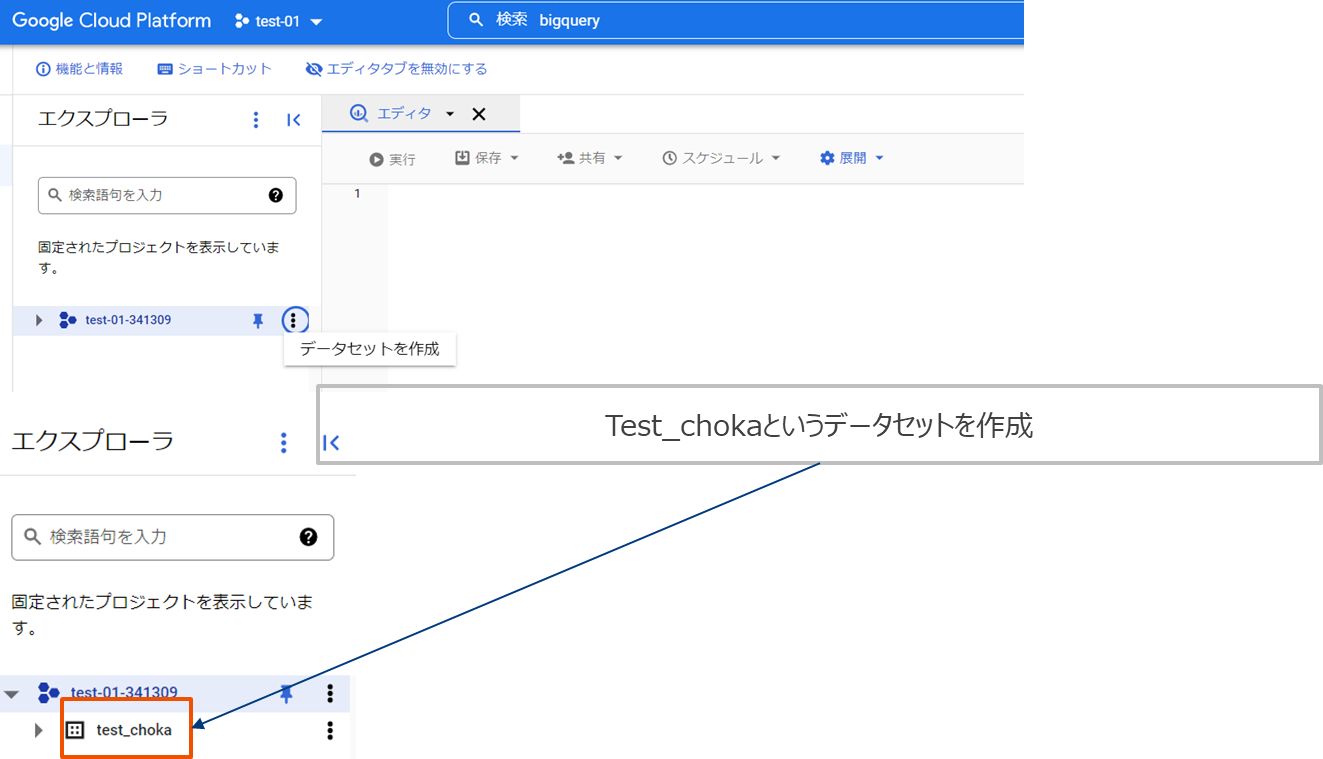
ローカルのshellからbqコマンドを使用してテーブルを作成します。
$ bq mk --table test_choka.choka_2017 name:string,num:int64,location:string,date:int64過去分(5年分)を取り込む
過去分(5年分)をStorageに取込み(gsutilコマンド)、作成したBigQueryのテーブルに追加していきます。
① ローカル→Storage
ローカル端末のシェルでgsutilコマンドを使用して取り込む。2017*となっているのは2017年のcsvすべてワイルドカード指定している。それを作成したバケット下のフォルダ「choka/2017」以下に転送するように命令している。(フォルダは指定すればバケット下に自動で作成される。)
gsutil cp /Users/[user名]/dev/data/2017*.csv gs://[バケット名]/[バケット下のフォルダ]/2017 #2017というフォルダにいれます② 2017-2022まで5年分行う。
③Storage→BiqQuery
クライントライブラリで作成したpythonスクリプトを使用してデータを転送し、あらかじめ作成したテーブルにアペンドしていく。test.pyという名前で作成(詳細は次ページ)。コマンドライン引数に年を指定。
Python test.py 2017④ 2017-2022まで5年分行う。
test.pyは引数に読み込みたい年の年数で、ローカルcsv→GCS→BQに一気にデータを入れる処理をします。
ここらへんを参考にしています。2https://dev.classmethod.jp/articles/bigquery-table-data-export2gcs/、3https://qiita.com/Hyperion13fleet/items/0e00f4070f623dacf92b、4https://colabmix.co.jp/tech-blog/python-google-cloud-bigquery-4/、5https://www.ai-shift.co.jp/techblog/1839
test.pyの中身
from google.cloud import bigquery
import time
import os
import numpy as np
import sys
args = sys.argv
year = str(args[1])
print (year)
# 読み込みCSVリストを作成
files = os.listdir("../dev/data")
files_dic = {}
# 月ごとに作成
for i in np.arange(1,13):
#print (i)
files_dic[i] = [f for f in files if f.find(year + str(i).zfill(2))>-1]
# 自身のGCPProjectIDを指定
project_id = [プロジェクトID]
client = bigquery.Client(project=project_id)
# データセット、テーブル名を指定
detaset_id = [データセット名]
table_id = [テーブル名]
dataset_ref = client.dataset("test_choka")
table_ref = dataset_ref.table(table_id)
# config
job_config = bigquery.LoadJobConfig()
job_config.skip_leading_rows = 0
job_config.source_format = bigquery.SourceFormat.CSV
for i in np.arange(1,13):
if files_dic[i]:
#print (files_dic[i])
for f in sorted(files_dic[i]):
print (f)
# GCSのファイルが置いてあるパスを指定
uri = "gs://[GCSのバケット名とcsvのあるフォルダ]"+f
# ジョブを生成
load_job = client.load_table_from_uri(
uri, table_ref, job_config=job_config
)
# ロードを実行
load_job.result()
# 60秒間待つ
time.sleep(120)実践 Google data portalに連携
Google data portalに連携
data portal連携前に、それ用のテーブルを作成します。2017-2022までを縦に結合したテーブルを作成。BQの画面から新規クエリ作成で行います。
CREATE TABLE test_choka.choka_all
AS
(
SELECT * FROM `****2017`
union all
SELECT * FROM `****2018`
union all
SELECT * FROM `****2019`
union all
SELECT * FROM `****2020`
union all
SELECT * FROM `****2021`
union all
SELECT * FROM `****2022`
)
****はそれぞれの年のテーブル名
GCS→BQの段階で同じテーブルに最初から入れておけばよいのであるが、運用上一応5つのテーブルに分けました。
適当にレポートを作成して共有します。
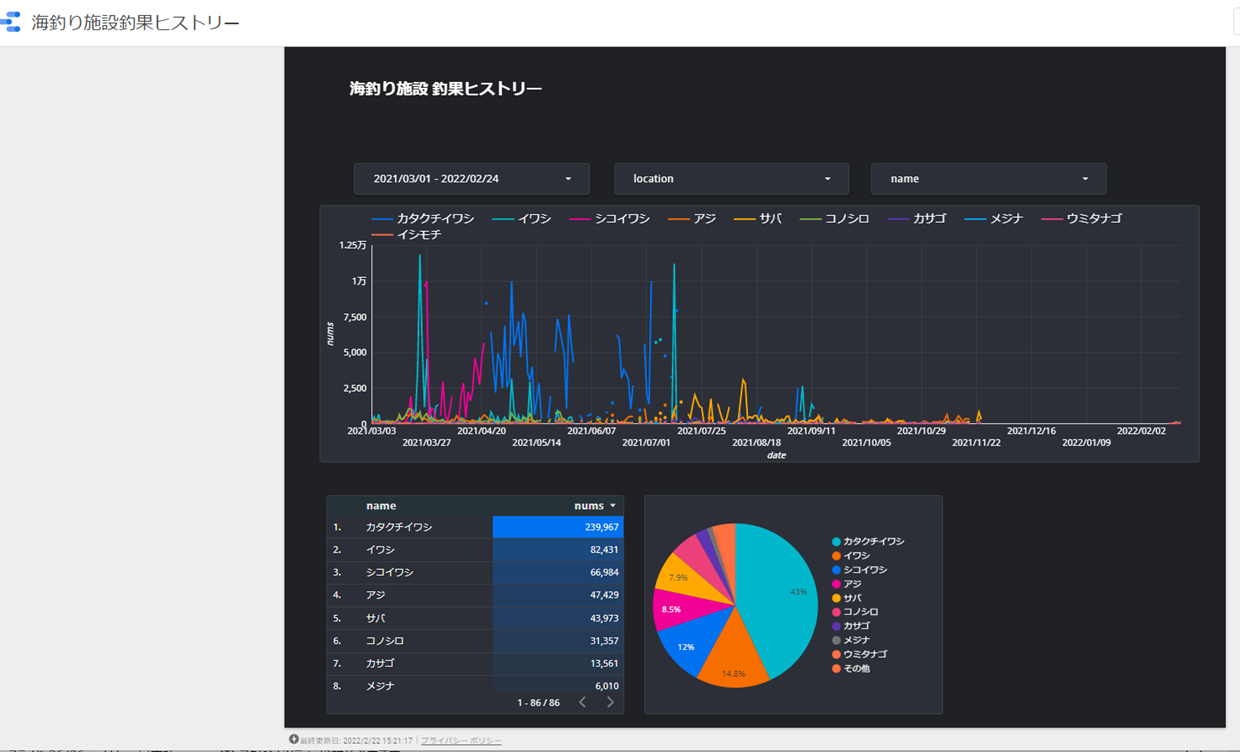
https://datastudio.google.com/u/0/reporting/339df563-d460-4b77-a415-0ec91cc202d3/page/e3OmC
後は毎日新しいデータを取得するバッチ処理を追加します。
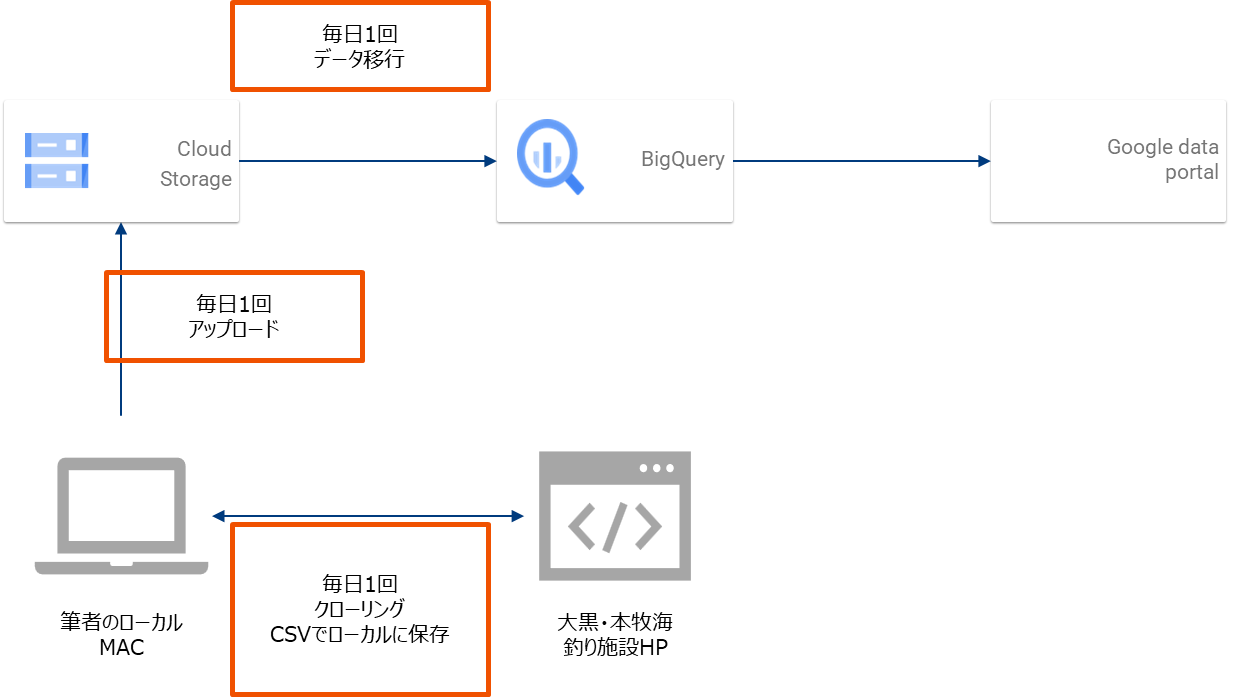
日次バッチ処理の構成
Pythonのcloud storageのクライントライブラリをインストールします。(Big Queryのクライントライブラリはすでにインストールした)
pip install google-cloud-storage
バッチ処理を毎日午後11:30分に行うようにスケジューリングします。
crontab(macやlinux系OSのタスクスケジューラ)を以下のように設定します。
Pythonはクライアントライブラリをインストールした環境下のpythonインタプリタを使用します。
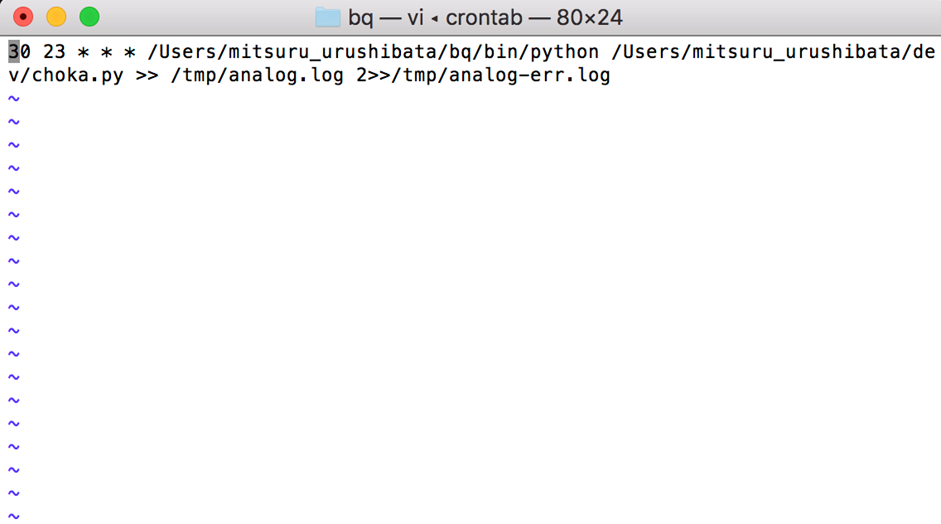
以上で完了です。
これで毎日クローリングと同時にGCS→BQへデータが連携され、DataPortalで釣果を確認できます。
残念なことに本牧施設は台風の影響で一部施設が損壊し、完全な稼働はできていません。実際に一番の釣果を誇った当施設も最近では磯子施設にお客さんが流れているで釣果も減少気味です。
GCPのデータ基盤の活用に関しては弊社までご相談ください。何卒宜しくお願い致します。