
PythonやRは今や機械学習・統計解析の実務についてはほぼ必須となるスキルです。データの加工やモデリング全てのフェーズにおいてそれらいずれかが用いられます。例外として有償ソフトウェアを使用できる企業に在籍していればSASやSPSSなどの選択肢がありますがそれは少数派でしょう。
従ってデータサイエンスをこれから学ぼうと思っているかたにとってもこれらの習得は避けて通ることができません。一方でこれらができること=データサイエンティストとして優秀は成立しません。特に顧客に対してサービスを提供する広告代理店やコンサルファームなどであれば顧客折衝力や課題設定力などのスキルの方が重要となります。
ところでPythonはプログラム言語のひとつであるため、そのような顧客と対峙する職業の方が学ぼうと思っても純粋なプログラマより苦慮する場合が多いようです。その理由としてPythonを用いたデータサイエンスの入門書がそのような職業の方にとって必要十分以上の内容になっていることが挙げられます。例えばとにかく顧客データを集計したい人にとってクラスの説明は冗長すぎます。
本稿ではとにかく早く集計や加工を学んでプロジェクトにアサインされたい若手やアサインしたい部下をもつマネージャーの方にどのようにPythonと付き合って学んでいくのかを述べたいと思います。
プログラム言語の習熟は必須ではないが…
扱うデータがせいぜい数万レコードでカラムも属性データ程度あればExcelで事足ります。Excelにはデータ解析の基本的なアドインがあり、相関分析及び回帰分析程度ならば可能です。複数ファイルが有る場合などはExcelだけでは辛いものがありますが、とにかく少数データの分析においてはExcelだけでも対応可能なのです。
一方でそのような理想的な状況じゃない場合、若手を仕事にアサインするためにはPythonやRの必要最低限の知識が必要となります。特にファイルが100近く有る場合にまとめて集計する場合などはそうです。
RとPythonどちら?
今までRとPythonと主語を二つにしてきましたが、個人的見解では初学者は迷ったらPythonを学ぶことをおすすめします。その理由としてPythonの方がユーザ人口が多いためドキュメントが豊富であること、今後もスタンダードとして使用されていく可能性が高いことがあります。以降ではPythonに論点を絞ります。
入門にならない入門書
Pythonの入門として有名な書物として以下が挙げられます。
しかし、データサイエンスをやりたい人、ましてやすぐに集計したい人がこの本を最初から通読するのはあまりに重いです。Pythonは元々Rと異なり機械学習や統計解析に特化した言語ではなくwebアプリケーションも作成できる汎用的な言語です。そのため非常に多くのことができる反面、学ぶことも多くなりがちです。
誤解を恐れずに言うならばデータサイエンスを目的として最低限の仕事のためにPythonを最初から体系的に学ぶことは時間の無駄です。
必要最低限はこれ
では必要最低限何を学べば良いでしょうか。まずは以下にPythonとデータサイエンスに必要な関連モジュールの俯瞰図を示します。
そしてデータ分析プロジェクトでのタスクフローを以下に示します。
 この中でデータの加工・集計のタスクは量も多く重要になってきます。そのため特にPython標準(他のモジュールを必要としないネイティブ)の中で数値/文字列オブジェクト、リスト、次いでpandasモジュールの中で必要なものについて学べば良いでしょう。実際にpythonでデータを扱うとき、ほとんどの場合でデータフレームとして扱うのでnumpyよりもpandasを先に学ぶ方が良いと思います。またscikit-learnはモデリングを行うとき以外不要です。データ加工・集計はどのようなプロジェクトでも必須ですが、モデリングはプロジェクトにおいては必須でない場合があるため、優先順位が下がります。またmatplotlibはグラフ描画用のモジュールですが、これはエクセルで代替できます。
この中でデータの加工・集計のタスクは量も多く重要になってきます。そのため特にPython標準(他のモジュールを必要としないネイティブ)の中で数値/文字列オブジェクト、リスト、次いでpandasモジュールの中で必要なものについて学べば良いでしょう。実際にpythonでデータを扱うとき、ほとんどの場合でデータフレームとして扱うのでnumpyよりもpandasを先に学ぶ方が良いと思います。またscikit-learnはモデリングを行うとき以外不要です。データ加工・集計はどのようなプロジェクトでも必須ですが、モデリングはプロジェクトにおいては必須でない場合があるため、優先順位が下がります。またmatplotlibはグラフ描画用のモジュールですが、これはエクセルで代替できます。
具体的な優先順位
まずPythonの入門書で必ず扱われる、「リスト内包表記」「lambda式」「クラス」は飛ばして結構です。これらは使いこなせれば非常に有用ですがなくても何とかなります。さらに初学者が学ぼうとするとつまずきのポイントでもあるのでここで無用な時間を潰してしまう可能性があるからです。後日もっと楽に早くコードを書きたいと思った時に適宜学べば良いでしょう。
次に必須なものをあげます。
リスト
まずはリストオブジェクトを理解すること、最低限リストの概念とその中身をどのように参照するかを理解します。またfor文と言う同一処理をループで回すときにも使用しますのでリストとfor文は同時に理解しましょう。その他にもリストと類似した辞書や集合がありますが、それらは後回しでOKです。
pandasとそのメソッドは大変重要です。
read
まずread_csvのようなcsvファイルやテキストファイルの読み込み方を覚えます。入門書ではリストや辞書からデータフレームをs区政する方法を紹介していることが多いですが、実務では95%の確率でcsvその他テキストファイルからデータフレームを作成します。
pd.mergeとpd.concat
データを読み込んだらそれを結合したりして必要なデータに加工します。そのために表題のmergeとconcatを使用します。両方ともpandasデータフレームを結合するために使用します。sqlをご存知の人はjoinやunionと同じと理解してください。
sum,mean,groupby
CRMデータでは金額の合計値が知りたい場合があります、そのために金額をの合計や平均を計算するsumやmeanについて学びます。また地域ごとに合計などグループごとにsumやmeanを行うためにgroupbyを学習すると効率が良いです。
文字列
文字列は例えばCRMデータ言えば都道府県などの日本語や英語でデータが格納されているものです。文字列に関しては何ができるかを理解して、あとは都度ググります。、文字列には関しては
①文字列同士を結合する
②文字列をある値で分割する
③文字列にある文字が含まれるものを返す(例えば東京と言う文字が住所にあるかないか)
文字列でできることは多すぎるため、とにかく何でもできるんだと言う理解で結構です。それをググれば良いだけです。
直近プロジェクトでの使用したメソッド等の分布
以下は直近私がクライアント向けに行ったマーケティング系の分析で用いたpythonのモジュールやメソッドの分布です。
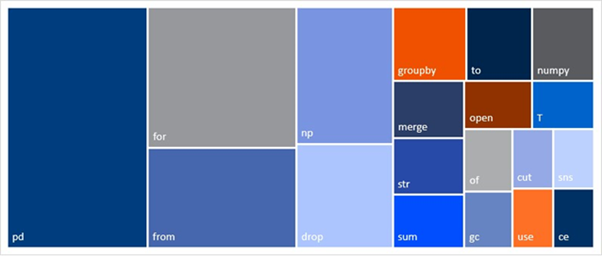
import などの外部モジュールを除けばmergeやdrop(カラム落とす)などのデータ加工系が多いことが分かります。またfor文も多いです。
優先順位のインデックス
以下は弊社(株式会社Crosstab)の初学者用の研修テキストの目次です。

特に*以外(すなわち無印)となっている箇所の優先順位が高い項目となっています。初学者の方はこれを参考に学んで頂ければ幸いです。
最後に
細かい仕様を覚える必要はないです、何が出来るか知るだけ後はググれば良いと言うことを肝に命じて下さい。慣れてくるとここをもっと早く便利に書けないかという欲求が出てくると思います、その時に初めてlamnda式やリスト内包表記、クラスの重要性に気づくでしょう。その時に学んだ方が効率が良いはずです。皆様が上達しプロのデータサイエンティストになることを応援しております。