
株式会社Crosstab 代表取締役 漆畑充
クロス集計はデータ分析の基本
弊社名「Crosstab」はクロス集計の英語名「cross tabulation」に由来します。単純ながら強力な手法であり、初期の段階で分析の方向性を定めるためや、データの加工の方法を検討したり、またモデル構築時に投入する変数を選択したりと様々な場所で有効です。このことよりクロス集計はデータ分析を行う上での基本中の基本と言っても過言ではありません。華やかなモデル構築ばかりに目がいきがちですが、弊社はこの基本を大事にするという思いからこの社名をつけました。
概要
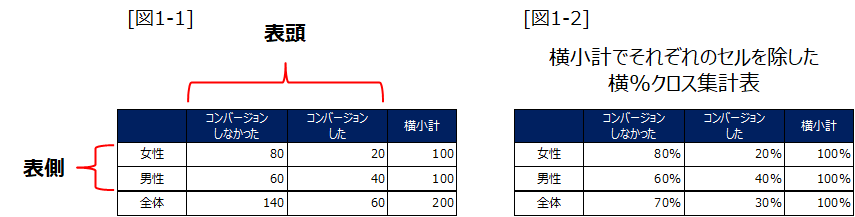
クロス集計は図1-1のように2つの異なる変数それぞれのカテゴリを表頭表側に並べて、それぞれの変数のカテゴリの組合せごとに集計する方法です。英語では「Contingency table」とも言うようで、1904年にピアソンが言及1“On the Theory of Contingency and Its Relation to Association and Normal Correlation” https://archive.org/details/cu31924003064833/page/n15/mode/2up したのが始めと言われています。
一般的に、表頭に目的変数(例えばクリックしたか、コンバージョンしたかのフラグなど)表側に説明変数を配置します。これを逆にやると素人かなと思われたりします。実際に実務で知りたいのは説明変数のもとでの目的変数の分布であるので(つまりP(Y|X))、横合計で除した横%版を用いることが多いです(図1-2)。例えばXが性別でYがコンバージョンフラグとすれば横%は男性/女性のコンバージョン率です。これも慣れない人は逆(つまりP(X|Y)、縦で除した縦%)を計算してしまうのですが、これだとコンバージョンした人の男性割合が分かるだけで、男性はコンバージョンしやすいのかどうかというのは分かりません。
役割
クロス集計は主に連続変数で言うところの散布図のような役割、つまりXとYに相関があるのかどうかを見るために使います。また連続変数であっても適当な閾値でカテゴリ化してしまえば、他のカテゴリ変数と横並びで相関の度合を比較することができます。連続量の相関係数に相当するものとしてχ2乗統計量があります。細かい計算式の定義はここでは触れませんが、Excelで簡単に計算できます。他にも分割票の赤池情報量基準(AIC) 2https://www.dynacom.co.jp/product_service/packages/snpalyze/sa_t2_aic-cont.html に詳しいやBICなどの情報量基準なども相関の度合として計算できます。
その他にも欠損の処理や外れ値処理の方法を検討したり、表側をネストさせることで説明変数の2つの組合せと目的変数との相関も見ることができます。マーケティングなどで機械学習モデルを構築するために、意味がある解釈可能なセグメントを定義しておく場合にこれを行う場合があります。例えば性別年齢と家族構成で消費傾向が異なるセグメントを作成したりです。勘の良い方はお気付きかと思いますが、表側をネストさせていくとカテゴリの値で分岐した決定木と見なせます。
機械学習全盛期においてあえてクロス集計を推す理由
現在の機械学習モデルは自動で変数を選択したり、さらにAutoMLともなれば前処理までほぼ自動で行うものもあります。このような時代にクロス集計のようなレガシーな手法の重要性を説く理由は、それがローデータの情報を最大限維持しつつ、また視認可能な最適な単位だからです。データ分析の基本は丹念に自分の目でデータを一つ一つ確認することですが、当然数万件のデータをつぶさにとなれば困難です。そのかわりにその最適な単位を確認することでデータを俯瞰しようというのです。
データを俯瞰できていれば、ローデータの持つバイアスや加工・集計ミスのようなプログラムがエラーメッセージを出力しないクリティカルな見落としもすぐ気が付くようになります。例えばプロジェクトも中盤になると、レコードの件数などは覚えてしまうため、マージ処理などのミスはすぐに分かります。また打合せの最中に、上司やお客様から急に「例えば男性の場合の数値はどうなっているの?」という問にもすぐに答えられます。「ああこいつは、こんなことも知らずに分析してたのか」と思われ信頼をなくすということもありません。
クロス集計を制する者はデータ分析を制するというのはこのような理由からです。
最後に
弊社は多数の説明変数と目的変数のクロス集計表を作成し、変数の重要度(χ2乗統計量)を算出する自社のツールを保有しています。
是非データ分析でお困りごとございましたら、弊社までご相談ください。